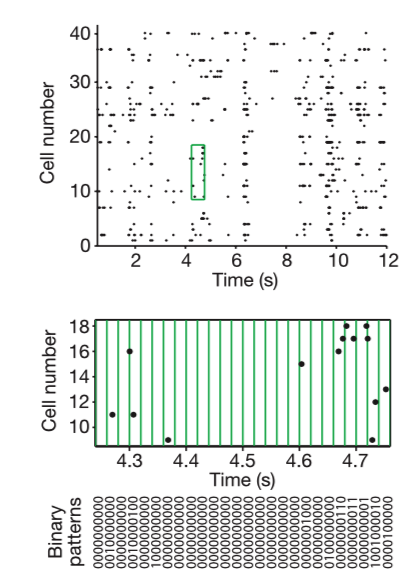
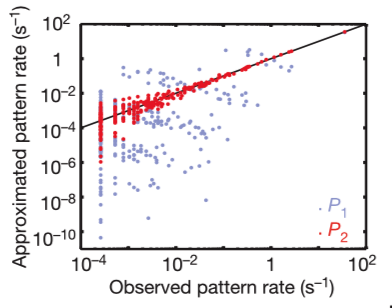
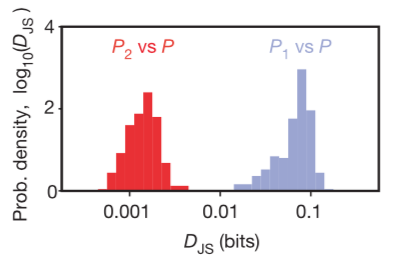
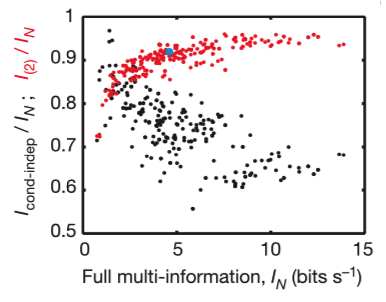
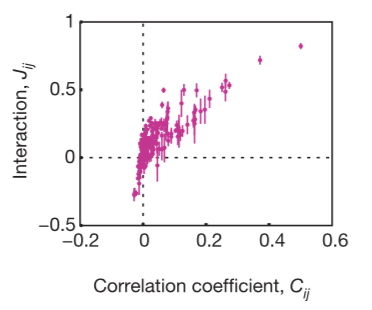
The periodic table below illustrates the global abundance of critical minerals in the Earth’s crust in parts per million (ppm). Hover over each element to view! Lanthanides and actinides are omitted due to lack of available data.
Data is obtained from the USGS handbook “Critical Mineral Resources of the United States— Economic and Environmental Geology and Prospects for Future Supply.” The code used is found here.
Bokeh Plot
https://cdn.pydata.org/bokeh/release/bokeh-1.4.0.min.js
Bokeh.set_log_level(“info”);
{“883d95fd-ecd4-4d16-ab52-790f2f46dd06”:{“roots”:{“references”:[{“attributes”:{“data_source”:{“id”:”1044″,”type”:”ColumnDataSource”},”glyph”:{“id”:”1046″,”type”:”Text”},”hover_glyph”:null,”muted_glyph”:null,”nonselection_glyph”:{“id”:”1047″,”type”:”Text”},”selection_glyph”:null,”view”:{“id”:”1049″,”type”:”CDSView”}},”id”:”1048″,”type”:”GlyphRenderer”},{“attributes”:{“callback”:null,”factors”:[“1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″]},”id”:”1002″,”type”:”FactorRange”},{“attributes”:{},”id”:”1073″,”type”:”UnionRenderers”},{“attributes”:{“text”:{“field”:”name”},”text_alpha”:{“value”:0.1},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”text_font_size”:{“value”:”5pt”},”x”:{“field”:”group”,”transform”:{“id”:”1029″,”type”:”Dodge”}},”y”:{“field”:”period”,”transform”:{“id”:”1043″,”type”:”Dodge”}}},”id”:”1047″,”type”:”Text”},{“attributes”:{“callback”:null,”factors”:[“VII”,”VI”,”V”,”IV”,”III”,”II”,”I”]},”id”:”1004″,”type”:”FactorRange”},{“attributes”:{},”id”:”1068″,”type”:”CategoricalTickFormatter”},{“attributes”:{“text”:{“field”:”atomic number”},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”text_font_size”:{“value”:”8pt”},”x”:{“field”:”group”,”transform”:{“id”:”1029″,”type”:”Dodge”}},”y”:{“field”:”period”,”transform”:{“id”:”1036″,”type”:”Dodge”}}},”id”:”1039″,”type”:”Text”},{“attributes”:{},”id”:”1069″,”type”:”UnionRenderers”},{“attributes”:{},”id”:”1072″,”type”:”Selection”},{“attributes”:{},”id”:”1006″,”type”:”CategoricalScale”},{“attributes”:{“text”:{“field”:”atomic number”},”text_alpha”:{“value”:0.1},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”text_font_size”:{“value”:”8pt”},”x”:{“field”:”group”,”transform”:{“id”:”1029″,”type”:”Dodge”}},”y”:{“field”:”period”,”transform”:{“id”:”1036″,”type”:”Dodge”}}},”id”:”1040″,”type”:”Text”},{“attributes”:{“range”:{“id”:”1004″,”type”:”FactorRange”},”value”:0.3},”id”:”1036″,”type”:”Dodge”},{“attributes”:{“text_align”:”center”,”text_alpha”:{“value”:0.1},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”x”:{“field”:”x”},”y”:{“field”:”y”}},”id”:”1059″,”type”:”Text”},{“attributes”:{},”id”:”1008″,”type”:”CategoricalScale”},{“attributes”:{“data_source”:{“id”:”1037″,”type”:”ColumnDataSource”},”glyph”:{“id”:”1039″,”type”:”Text”},”hover_glyph”:null,”muted_glyph”:null,”nonselection_glyph”:{“id”:”1040″,”type”:”Text”},”selection_glyph”:null,”view”:{“id”:”1042″,”type”:”CDSView”}},”id”:”1041″,”type”:”GlyphRenderer”},{“attributes”:{“text_align”:”center”,”text_baseline”:”middle”,”text_color”:{“value”:”black”},”x”:{“field”:”x”},”y”:{“field”:”y”}},”id”:”1058″,”type”:”Text”},{“attributes”:{“axis_line_color”:{“value”:null},”formatter”:{“id”:”1066″,”type”:”CategoricalTickFormatter”},”major_label_standoff”:0,”major_tick_line_color”:{“value”:null},”ticker”:{“id”:”1011″,”type”:”CategoricalTicker”}},”id”:”1010″,”type”:”CategoricalAxis”},{“attributes”:{“source”:{“id”:”1037″,”type”:”ColumnDataSource”}},”id”:”1042″,”type”:”CDSView”},{“attributes”:{“callback”:null,”data”:{“text”:[“LA”,”AC”],”x”:[“3″,”3″],”y”:[“VI”,”VII”]},”selected”:{“id”:”1080″,”type”:”Selection”},”selection_policy”:{“id”:”1079″,”type”:”UnionRenderers”}},”id”:”1057″,”type”:”ColumnDataSource”},{“attributes”:{“callback”:null,”data”:{“CPK”:[“#FFFFFF”,”#D9FFFF”,”#CC80FF”,”#C2FF00″,”#FFB5B5″,”#909090″,”#3050F8″,”#FF0D0D”,”#90E050″,”#B3E3F5″,”#AB5CF2″,”#8AFF00″,”#BFA6A6″,”#F0C8A0″,”#FF8000″,”#FFFF30″,”#1FF01F”,”#80D1E3″,”#8F40D4″,”#3DFF00″,”#E6E6E6″,”#BFC2C7″,”#A6A6AB”,”#8A99C7″,”#9C7AC7″,”#E06633″,”#F090A0″,”#50D050″,”#C88033″,”#7D80B0″,”#C28F8F”,”#668F8F”,”#BD80E3″,”#FFA100″,”#A62929″,”#5CB8D1″,”#702EB0″,”#00FF00″,”#94FFFF”,”#94E0E0″,”#73C2C9″,”#54B5B5″,”#3B9E9E”,”#248F8F”,”#0A7D8C”,”#006985″,”#C0C0C0″,”#FFD98F”,”#A67573″,”#668080″,”#9E63B5″,”#D47A00″,”#940094″,”#429EB0″,”#57178F”,”#00C900″,”#4DC2FF”,”#4DA6FF”,”#2194D6″,”#267DAB”,”#266696″,”#175487″,”#D0D0E0″,”#FFD123″,”#B8B8D0″,”#A6544D”,”#575961″,”#9E4FB5″,”#AB5C00″,”#754F45″,”#428296″,”#420066″,”#007D00″,”#CC0059″,”#D1004F”,”#D90045″,”#E00038″,”#E6002E”,”#EB0026″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″],”EA”:{“__ndarray__”:”AAAAAABAUsAAAAAAAAAAAAAAAAAAAE7AAAAAAAAAAAAAAAAAAAA7wAAAAAAAQGPAAAAAAAAAHMAAAAAAAKBhwAAAAAAAgHTAAAAAAAAAAAAAAAAAAIBKwAAAAAAAAAAAAAAAAACARcAAAAAAAMBgwAAAAAAAAFLAAAAAAAAAacAAAAAAANB1wAAAAAAAAAAAAAAAAAAASMAAAAAAAAAAwAAAAAAAADLAAAAAAAAAIMAAAAAAAIBJwAAAAAAAAFDAAAAAAAAAAAAAAAAAAAAwwAAAAAAAAFDAAAAAAAAAXMAAAAAAAIBdwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBdwAAAAAAAgFPAAAAAAABgaMAAAAAAAFB0wAAAAAAAAAAAAAAAAACAR8AAAAAAAAAUwAAAAAAAAD7AAAAAAACARMAAAAAAAIBVwAAAAAAAAFLAAAAAAACASsAAAAAAAEBZwAAAAAAAgFvAAAAAAAAAS8AAAAAAAIBfwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBawAAAAAAAwFnAAAAAAADAZ8AAAAAAAHBywAAAAAAAAAAAAAAAAAAAR8AAAAAAAAAswAAAAAAAAAAAAAAAAAAAP8AAAAAAAMBTwAAAAAAAAC7AAAAAAACAWsAAAAAAAOBiwAAAAAAAoGnAAAAAAADga8AAAAAAAAAAAAAAAAAAADPAAAAAAACAQcAAAAAAAMBWwAAAAAAA4GbAAAAAAADgcMAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”IE-1″:{“__ndarray__”:”AAAAAACAlEAAAAAAAIiiQAAAAAAAQIBAAAAAAAAgjEAAAAAAAAiJQAAAAAAA/JBAAAAAAADolUAAAAAAAIiUQAAAAAAARJpAAAAAAABCoEAAAAAAAAB/QAAAAAAAEIdAAAAAAAAQgkAAAAAAAJiIQAAAAAAAoI9AAAAAAABAj0AAAAAAAIyTQAAAAAAAxJdAAAAAAAAwekAAAAAAAHCCQAAAAAAAyINAAAAAAACYhEAAAAAAAFiEQAAAAAAAaIRAAAAAAABohkAAAAAAANiHQAAAAAAAwIdAAAAAAAAIh0AAAAAAAFCHQAAAAAAAUIxAAAAAAAAYgkAAAAAAANCHQAAAAAAAmI1AAAAAAABojUAAAAAAANCRQAAAAAAAHJVAAAAAAAAweUAAAAAAADCBQAAAAAAAwIJAAAAAAAAAhEAAAAAAAGCEQAAAAAAAYIVAAAAAAADwhUAAAAAAADCGQAAAAAAAgIZAAAAAAAAgiUAAAAAAANiGQAAAAAAAIItAAAAAAABwgUAAAAAAACiGQAAAAAAAEIpAAAAAAAAoi0AAAAAAAICPQAAAAAAASJJAAAAAAACAd0AAAAAAAHB/QAAAAAAAmIRAAAAAAADIh0AAAAAAABCIQAAAAAAAwIdAAAAAAABAikAAAAAAAICLQAAAAAAAMItAAAAAAADQi0AAAAAAAHiPQAAAAAAAaIJAAAAAAABghkAAAAAAAPiFQAAAAAAAYIlAAAAAAADAjEAAAAAAADSQQAAAAAAAwHdAAAAAAADQf0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”atomic mass”:[“1.00794″,”4.002602″,”6.941″,”9.012182″,”10.811″,”12.0107″,”14.0067″,”15.9994″,”18.9984032″,”20.1797″,”22.98976928″,”24.3050″,”26.9815386″,”28.0855″,”30.973762″,”32.065″,”35.453″,”39.948″,”39.0983″,”40.078″,”44.955912″,”47.867″,”50.9415″,”51.9961″,”54.938045″,”55.845″,”58.933195″,”58.6934″,”63.546″,”65.38″,”69.723″,”72.64″,”74.92160″,”78.96″,”79.904″,”83.798″,”85.4678″,”87.62″,”88.90585″,”91.224″,”92.90638″,”95.96″,”[98]”,”101.07″,”102.90550″,”106.42″,”107.8682″,”112.411″,”114.818″,”118.710″,”121.760″,”127.60″,”126.90447″,”131.293″,”132.9054519″,”137.327″,”178.49″,”180.94788″,”183.84″,”186.207″,”190.23″,”192.217″,”195.084″,”196.966569″,”200.59″,”204.3833″,”207.2″,”208.98040″,”[209]”,”[210]”,”[222]”,”[223]”,”[226]”,”[267]”,”[268]”,”[271]”,”[272]”,”[270]”,”[276]”,”[281]”,”[280]”,”[285]”,”[284]”,”[289]”,”[288]”,”[293]”,”[294]”,”[294]”],”atomic number”:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118],”atomic radius”:{“__ndarray__”:”AAAAAACAQkAAAAAAAABAQAAAAAAAwGBAAAAAAACAVkAAAAAAAIBUQAAAAAAAQFNAAAAAAADAUkAAAAAAAEBSQAAAAAAAwFFAAAAAAABAUUAAAAAAAEBjQAAAAAAAQGBAAAAAAACAXUAAAAAAAMBbQAAAAAAAgFpAAAAAAACAWUAAAAAAAMBYQAAAAAAAQFhAAAAAAACAaEAAAAAAAMBlQAAAAAAAAGJAAAAAAAAAYUAAAAAAAEBfQAAAAAAAwF9AAAAAAABgYUAAAAAAAEBfQAAAAAAAgF9AAAAAAABAXkAAAAAAAEBhQAAAAAAAYGBAAAAAAACAX0AAAAAAAIBeQAAAAAAAwF1AAAAAAAAAXUAAAAAAAIBcQAAAAAAAgFtAAAAAAABgakAAAAAAAABoQAAAAAAAQGRAAAAAAACAYkAAAAAAACBhQAAAAAAAIGJAAAAAAACAY0AAAAAAAIBfQAAAAAAA4GBAAAAAAABgYEAAAAAAACBjQAAAAAAAgGJAAAAAAAAAYkAAAAAAAKBhQAAAAAAAQGFAAAAAAADgYEAAAAAAAKBgQAAAAAAAQGBAAAAAAAAgbEAAAAAAAMBoQAAAAAAAwGJAAAAAAABAYUAAAAAAAEBiQAAAAAAA4GNAAAAAAAAAYEAAAAAAACBhQAAAAAAAAGBAAAAAAAAAYkAAAAAAAKBiQAAAAAAAgGJAAAAAAABgYkAAAAAAAEBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAACBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”boiling point”:{“__ndarray__”:”AAAAAAAANEAAAAAAAAAQQAAAAAAAPJlAAAAAAABupUAAAAAAALGwQAAAAAAAzLBAAAAAAABAU0AAAAAAAIBWQAAAAAAAQFVAAAAAAAAAO0AAAAAAABCSQAAAAAAATJVAAAAAAADQpUAAAAAAAMqoQAAAAAAAUIFAAAAAAABwhkAAAAAAAOBtQAAAAAAAwFVAAAAAAAAgkEAAAAAAAHSbQAAAAAAAPqhAAAAAAADQq0AAAAAAAMCsQAAAAAAAAKdAAAAAAAA8okAAAAAAAHyoQAAAAAAAAKlAAAAAAADkqEAAAAAAAACpQAAAAAAAcJJAAAAAAABao0AAAAAAACqoQAAAAAAAuItAAAAAAADwjUAAAAAAAMB0QAAAAAAAAF5AAAAAAAAIjkAAAAAAANyZQAAAAAAARKxAAAAAAABKskAAAAAAAJmzQAAAAAAAMLNAAAAAAAC6sUAAAAAAAEexQAAAAAAAAK9AAAAAAABIqUAAAAAAAAajQAAAAAAAQJBAAAAAAABSokAAAAAAAHamQAAAAAAAEJ1AAAAAAAC0k0AAAAAAAJB8QAAAAAAAoGRAAAAAAACAjUAAAAAAAL6gQAAAAAAADLNAAAAAAABjtkAAAAAAAMS2QAAAAAAA7bZAAAAAAACltEAAAAAAAF2yQAAAAAAAArBAAAAAAAByqEAAAAAAALCDQAAAAAAASJtAAAAAAACYn0AAAAAAALScQAAAAAAATJNAAAAAAAAA+H8AAAAAAGBqQAAAAAAAAPh/AAAAAABon0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”bonding type”:[“diatomic”,”atomic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”diatomic”,”diatomic”,”atomic”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”ca”:[0,0,118,318,0,0,0,0,106,0,0,0,0,0,0,0,0,0,0,0,52,121,81,0,38,0,212,0,0,0,452,23,0,0,0,0,0,0,52,27,59,0,0,153,153,153,0,0,28,113,34,68,0,0,0,41,27,59,0,101,153,153,153,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],”density”:{“__ndarray__”:”4yZZPRaRFz8AAAAAAAAAAEjhehSuR+E/mpmZmZmZ/T+uR+F6FK4DQBSuR+F6FAJAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAK16NwPQrvP9ejcD0K1/s/mpmZmZmZBUCkcD0K16MCQB+F61G4Hv0/XI/C9Shc/z8AAAAAAAAAAAAAAAAAAAAAhetRuB6F6z/NzMzMzMz4P+xRuB6F6wdACtejcD0KEkBxPQrXo3AYQI/C9ShcjxxA4XoUrkfhHUB7FK5H4XofQM3MzMzMzCFAUrgehevRIUDXo3A9CtchQI/C9ShcjxxAmpmZmZmZF0BI4XoUrkcVQOxRuB6F6xZASOF6FK5HE0D2KFyPwvUIQAAAAAAAAAAAexSuR+F6+D8K16NwPQoFQOF6FK5H4RFACtejcD0KGkCkcD0K1yMhQI/C9ShcjyRAAAAAAAAAJ0A9CtejcL0oQGZmZmZm5ihACtejcD0KKEB7FK5H4fokQM3MzMzMTCFAPQrXo3A9HUA9CtejcD0dQM3MzMzMzBpA9ihcj8L1GEDD9Shcj8ITQHsUrkfheoQ/FK5H4XoU/j8UrkfhehQMQB+F61G4nipAZmZmZmamMEAAAAAAAEAzQIXrUbgeBTVA16NwPQqXNkCPwvUoXI82QNejcD0KFzVAzczMzMxMM0CPwvUoXA8rQDMzMzMzsydArkfhehSuJkCPwvUoXI8jQGZmZmZmZiJAAAAAAAAA+H97FK5H4XqEPwAAAAAAAPh/AAAAAAAAFEAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronegativity”:{“__ndarray__”:”mpmZmZmZAUAAAAAAAAD4f1yPwvUoXO8/H4XrUbge+T9SuB6F61EAQGZmZmZmZgRAUrgehetRCECF61G4HoULQNejcD0K1w9AAAAAAAAA+H/D9Shcj8LtP/YoXI/C9fQ/w/UoXI/C+T9mZmZmZmb+P4XrUbgehQFApHA9CtejBEBI4XoUrkcJQAAAAAAAAPh/PQrXo3A96j8AAAAAAADwP8P1KFyPwvU/pHA9Ctej+D8UrkfhehT6P4/C9Shcj/o/zczMzMzM+D9I4XoUrkf9PxSuR+F6FP4/j8L1KFyP/j9mZmZmZmb+P2ZmZmZmZvo/9ihcj8L1/D8UrkfhehQAQHE9CtejcAFAZmZmZmZmBECuR+F6FK4HQAAAAAAAAPh/PQrXo3A96j9mZmZmZmbuP4XrUbgehfM/SOF6FK5H9T+amZmZmZn5P0jhehSuRwFAZmZmZmZm/j+amZmZmZkBQD0K16NwPQJAmpmZmZmZAUDhehSuR+H+PwrXo3A9Cvs/exSuR+F6/D9cj8L1KFz/P2ZmZmZmZgBAzczMzMzMAEBI4XoUrkcFQAAAAAAAAPh/SOF6FK5H6T97FK5H4XrsP83MzMzMzPQ/AAAAAAAA+D/hehSuR+ECQGZmZmZmZv4/mpmZmZmZAUCamZmZmZkBQD0K16NwPQJAUrgehetRBEAAAAAAAAAAQFK4HoXrUQBApHA9CtejAkApXI/C9SgAQAAAAAAAAABAmpmZmZmZAUAAAAAAAAD4f2ZmZmZmZuY/zczMzMzM7D8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronic configuration”:[“1s1″,”1s2″,”[He] 2s1″,”[He] 2s2″,”[He] 2s2 2p1″,”[He] 2s2 2p2″,”[He] 2s2 2p3″,”[He] 2s2 2p4″,”[He] 2s2 2p5″,”[He] 2s2 2p6″,”[Ne] 3s1″,”[Ne] 3s2″,”[Ne] 3s2 3p1″,”[Ne] 3s2 3p2″,”[Ne] 3s2 3p3″,”[Ne] 3s2 3p4″,”[Ne] 3s2 3p5″,”[Ne] 3s2 3p6″,”[Ar] 4s1″,”[Ar] 4s2″,”[Ar] 3d1 4s2″,”[Ar] 3d2 4s2″,”[Ar] 3d3 4s2″,”[Ar] 3d5 4s1″,”[Ar] 3d5 4s2″,”[Ar] 3d6 4s2″,”[Ar] 3d7 4s2″,”[Ar] 3d8 4s2″,”[Ar] 3d10 4s1″,”[Ar] 3d10 4s2″,”[Ar] 3d10 4s2 4p1″,”[Ar] 3d10 4s2 4p2″,”[Ar] 3d10 4s2 4p3″,”[Ar] 3d10 4s2 4p4″,”[Ar] 3d10 4s2 4p5″,”[Ar] 3d10 4s2 4p6″,”[Kr] 5s1″,”[Kr] 5s2″,”[Kr] 4d1 5s2″,”[Kr] 4d2 5s2″,”[Kr] 4d4 5s1″,”[Kr] 4d5 5s1″,”[Kr] 4d5 5s2″,”[Kr] 4d7 5s1″,”[Kr] 4d8 5s1″,”[Kr] 4d10″,”[Kr] 4d10 5s1″,”[Kr] 4d10 5s2″,”[Kr] 4d10 5s2 5p1″,”[Kr] 4d10 5s2 5p2″,”[Kr] 4d10 5s2 5p3″,”[Kr] 4d10 5s2 5p4″,”[Kr] 4d10 5s2 5p5″,”[Kr] 4d10 5s2 5p6″,”[Xe] 6s1″,”[Xe] 6s2″,”[Xe] 4f14 5d2 6s2″,”[Xe] 4f14 5d3 6s2″,”[Xe] 4f14 5d4 6s2″,”[Xe] 4f14 5d5 6s2″,”[Xe] 4f14 5d6 6s2″,”[Xe] 4f14 5d7 6s2″,”[Xe] 4f14 5d9 6s1″,”[Xe] 4f14 5d10 6s1″,”[Xe] 4f14 5d10 6s2″,”[Xe] 4f14 5d10 6s2 6p1″,”[Xe] 4f14 5d10 6s2 6p2″,”[Xe] 4f14 5d10 6s2 6p3″,”[Xe] 4f14 5d10 6s2 6p4″,”[Xe] 4f14 5d10 6s2 6p5″,”[Xe] 4f14 5d10 6s2 6p6″,”[Rn] 7s1″,”[Rn] 7s2″,”[Rn] 5f14 6d2 7s2″,”[Rn].5f14.6d3.7s2″,”[Rn].5f14.6d4.7s2″,”[Rn].5f14.6d5.7s2″,”[Rn].5f14.6d6.7s2″,”[Rn].5f14.6d7.7s2″,”[Rn].5f14.6d9.7s1″,”[Rn].5f14.6d10.7s1″,”[Rn].5f14.6d10.7s2″,”[Rn].5f14.6d10.7s2.7p1″,”[Rn].5f14.6d10.7s2.7p2″,”[Rn].5f14.6d10.7s2.7p3″,”[Rn].5f14.6d10.7s2.7p4″,”[Rn].5f14.6d10.7s2.7p5″,”[Rn].5f14.6d10.7s2.7p6″],”group”:[“1″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″],”index”:[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117],”ion radius”:[“NaN”,”NaN”,”76 (+1)”,”45 (+2)”,”27 (+3)”,”16 (+4)”,”146 (-3)”,”140 (-2)”,”133 (-1)”,”NaN”,”102 (+1)”,”72 (+2)”,”53.5 (+3)”,”40 (+4)”,”44 (+3)”,”184 (-2)”,”181 (-1)”,”NaN”,”138 (+1)”,”100 (+2)”,”74.5 (+3)”,”86 (+2)”,”79 (+2)”,”80 (+2*)”,”67 (+2)”,”78 (+2*)”,”74.5 (+2*)”,”69 (+2)”,”77 (+1)”,”74 (+2)”,”62 (+3)”,”73 (+2)”,”58 (+3)”,”198 (-2)”,”196 (-1)”,”NaN”,”152 (+1)”,”118 (+2)”,”90 (+3)”,”72 (+4)”,”72 (+3)”,”69 (+3)”,”64.5 (+4)”,”68 (+3)”,”66.5 (+3)”,”59 (+1)”,”115 (+1)”,”95 (+2)”,”80 (+3)”,”112 (+2)”,”76 (+3)”,”221 (-2)”,”220 (-1)”,”48 (+8)”,”167 (+1)”,”135 (+2)”,”71 (+4)”,”72 (+3)”,”66 (+4)”,”63 (+4)”,”63 (+4)”,”68 (+3)”,”86 (+2)”,”137 (+1)”,”119 (+1)”,”150 (+1)”,”119 (+2)”,”103 (+3)”,”94 (+4)”,”62 (+7)”,”NaN”,”180 (+1)”,”148 (+2)”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”melting point”:{“__ndarray__”:”AAAAAAAALEAAAAAAAAD4fwAAAAAAYHxAAAAAAABgmEAAAAAAAFiiQAAAAAAA3q1AAAAAAACAT0AAAAAAAIBLQAAAAAAAAEtAAAAAAAAAOUAAAAAAADB3QAAAAAAA2IxAAAAAAAAojUAAAAAAAFyaQAAAAAAA0HNAAAAAAABAeEAAAAAAAIBlQAAAAAAAAFVAAAAAAAAQdUAAAAAAAGyRQAAAAAAAWJxAAAAAAABUnkAAAAAAAA6hQAAAAAAACKFAAAAAAAC8l0AAAAAAAEycQAAAAAAAoJtAAAAAAAAAm0AAAAAAADiVQAAAAAAAqIVAAAAAAADwckAAAAAAAOySQAAAAAAACJFAAAAAAADgfkAAAAAAAKBwQAAAAAAAAF1AAAAAAACAc0AAAAAAAGiQQAAAAAAAHJxAAAAAAACgoEAAAAAAAHylQAAAAAAAoKZAAAAAAAD8okAAAAAAAF6kQAAAAAAAeqFAAAAAAACQnEAAAAAAAEyTQAAAAAAAkIJAAAAAAADgekAAAAAAAJB/QAAAAAAAQIxAAAAAAACYhkAAAAAAADB4QAAAAAAAIGRAAAAAAADgckAAAAAAAECPQAAAAAAAlKNAAAAAAAC0qUAAAAAAAN6sQAAAAAAABqtAAAAAAADUqUAAAAAAAGalQAAAAAAA5J9AAAAAAADklEAAAAAAAEBtQAAAAAAACIJAAAAAAADIgkAAAAAAAACBQAAAAAAAeIBAAAAAAAD4gUAAAAAAAEBpQAAAAAAAAPh/AAAAAABojkAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”metal”:[“nonmetal”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metalloid”,”nonmetal”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metal”,”metalloid”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metalloid”,”metalloid”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metalloid”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metal”,”halogen”,”noble gas”],”name”:[“Hydrogen”,”Helium”,”Lithium”,”Beryllium”,”Boron”,”Carbon”,”Nitrogen”,”Oxygen”,”Fluorine”,”Neon”,”Sodium”,”Magnesium”,”Aluminum”,”Silicon”,”Phosphorus”,”Sulfur”,”Chlorine”,”Argon”,”Potassium”,”Calcium”,”Scandium”,”Titanium”,”Vanadium”,”Chromium”,”Manganese”,”Iron”,”Cobalt”,”Nickel”,”Copper”,”Zinc”,”Gallium”,”Germanium”,”Arsenic”,”Selenium”,”Bromine”,”Krypton”,”Rubidium”,”Strontium”,”Yttrium”,”Zirconium”,”Niobium”,”Molybdenum”,”Technetium”,”Ruthenium”,”Rhodium”,”Palladium”,”Silver”,”Cadmium”,”Indium”,”Tin”,”Antimony”,”Tellurium”,”Iodine”,”Xenon”,”Cesium”,”Barium”,”Hafnium”,”Tantalum”,”Tungsten”,”Rhenium”,”Osmium”,”Iridium”,”Platinum”,”Gold”,”Mercury”,”Thallium”,”Lead”,”Bismuth”,”Polonium”,”Astatine”,”Radon”,”Francium”,”Radium”,”Rutherfordium”,”Dubnium”,”Seaborgium”,”Bohrium”,”Hassium”,”Meitnerium”,”Darmstadtium”,”Roentgenium”,”Copernicium”,”Nihomium”,”Flerovium”,”Moscovium”,”Livermorium”,”Tennessine”,”Oganesson”],”period”:[“I”,”I”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”],”standard state”:[“gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”symbol”:[“H”,”He”,”Li”,”Be”,”B”,”C”,”N”,”O”,”F”,”Ne”,”Na”,”Mg”,”Al”,”Si”,”P”,”S”,”Cl”,”Ar”,”K”,”Ca”,”Sc”,”Ti”,”V”,”Cr”,”Mn”,”Fe”,”Co”,”Ni”,”Cu”,”Zn”,”Ga”,”Ge”,”As”,”Se”,”Br”,”Kr”,”Rb”,”Sr”,”Y”,”Zr”,”Nb”,”Mo”,”Tc”,”Ru”,”Rh”,”Pd”,”Ag”,”Cd”,”In”,”Sn”,”Sb”,”Te”,”I”,”Xe”,”Cs”,”Ba”,”Hf”,”Ta”,”W”,”Re”,”Os”,”Ir”,”Pt”,”Au”,”Hg”,”Tl”,”Pb”,”Bi”,”Po”,”At”,”Rn”,”Fr”,”Ra”,”Rf”,”Db”,”Sg”,”Bh”,”Hs”,”Mt”,”Ds”,”Rg”,”Cn”,”Nh”,”Fl”,”Mc”,”Lv”,”Ts”,”Og”],”van der Waals radius”:{“__ndarray__”:”AAAAAAAAXkAAAAAAAIBhQAAAAAAAwGZAAAAAAAAA+H8AAAAAAAD4fwAAAAAAQGVAAAAAAABgY0AAAAAAAABjQAAAAAAAYGJAAAAAAABAY0AAAAAAAGBsQAAAAAAAoGVAAAAAAAAA+H8AAAAAAEBqQAAAAAAAgGZAAAAAAACAZkAAAAAAAOBlQAAAAAAAgGdAAAAAAAAwcUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBhQAAAAAAAYGFAAAAAAABgZ0AAAAAAAAD4fwAAAAAAIGdAAAAAAADAZ0AAAAAAACBnQAAAAAAAQGlAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBlQAAAAAAAwGNAAAAAAAAgaEAAAAAAACBrQAAAAAAAAPh/AAAAAADAaUAAAAAAAMBoQAAAAAAAAGtAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAA4GVAAAAAAADAZEAAAAAAAGBjQAAAAAAAgGhAAAAAAABAaUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”year discovered”:[“1766″,”1868″,”1817″,”1798″,”1807″,”Ancient”,”1772″,”1774″,”1670″,”1898″,”1807″,”1808″,”Ancient”,”1854″,”1669″,”Ancient”,”1774″,”1894″,”1807″,”Ancient”,”1876″,”1791″,”1803″,”Ancient”,”1774″,”Ancient”,”Ancient”,”1751″,”Ancient”,”1746″,”1875″,”1886″,”Ancient”,”1817″,”1826″,”1898″,”1861″,”1790″,”1794″,”1789″,”1801″,”1778″,”1937″,”1827″,”1803″,”1803″,”Ancient”,”1817″,”1863″,”Ancient”,”Ancient”,”1782″,”1811″,”1898″,”1860″,”1808″,”1923″,”1802″,”1783″,”1925″,”1803″,”1803″,”Ancient”,”Ancient”,”Ancient”,”1861″,”Ancient”,”Ancient”,”1898″,”1940″,”1900″,”1939″,”1898″,”1969″,”1967″,”1974″,”1976″,”1984″,”1982″,”1994″,”1994″,”1996″,”2003″,”1998″,”2003″,”2000″,”2010″,”2002″]},”selected”:{“id”:”1072″,”type”:”Selection”},”selection_policy”:{“id”:”1071″,”type”:”UnionRenderers”}},”id”:”1030″,”type”:”ColumnDataSource”},{“attributes”:{},”id”:”1011″,”type”:”CategoricalTicker”},{“attributes”:{“range”:{“id”:”1004″,”type”:”FactorRange”},”value”:-0.35},”id”:”1043″,”type”:”Dodge”},{“attributes”:{“source”:{“id”:”1051″,”type”:”ColumnDataSource”}},”id”:”1056″,”type”:”CDSView”},{“attributes”:{“grid_line_color”:null,”ticker”:{“id”:”1011″,”type”:”CategoricalTicker”}},”id”:”1013″,”type”:”Grid”},{“attributes”:{“callback”:null,”data”:{“CPK”:[“#FFFFFF”,”#D9FFFF”,”#CC80FF”,”#C2FF00″,”#FFB5B5″,”#909090″,”#3050F8″,”#FF0D0D”,”#90E050″,”#B3E3F5″,”#AB5CF2″,”#8AFF00″,”#BFA6A6″,”#F0C8A0″,”#FF8000″,”#FFFF30″,”#1FF01F”,”#80D1E3″,”#8F40D4″,”#3DFF00″,”#E6E6E6″,”#BFC2C7″,”#A6A6AB”,”#8A99C7″,”#9C7AC7″,”#E06633″,”#F090A0″,”#50D050″,”#C88033″,”#7D80B0″,”#C28F8F”,”#668F8F”,”#BD80E3″,”#FFA100″,”#A62929″,”#5CB8D1″,”#702EB0″,”#00FF00″,”#94FFFF”,”#94E0E0″,”#73C2C9″,”#54B5B5″,”#3B9E9E”,”#248F8F”,”#0A7D8C”,”#006985″,”#C0C0C0″,”#FFD98F”,”#A67573″,”#668080″,”#9E63B5″,”#D47A00″,”#940094″,”#429EB0″,”#57178F”,”#00C900″,”#4DC2FF”,”#4DA6FF”,”#2194D6″,”#267DAB”,”#266696″,”#175487″,”#D0D0E0″,”#FFD123″,”#B8B8D0″,”#A6544D”,”#575961″,”#9E4FB5″,”#AB5C00″,”#754F45″,”#428296″,”#420066″,”#007D00″,”#CC0059″,”#D1004F”,”#D90045″,”#E00038″,”#E6002E”,”#EB0026″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″],”EA”:{“__ndarray__”:”AAAAAABAUsAAAAAAAAAAAAAAAAAAAE7AAAAAAAAAAAAAAAAAAAA7wAAAAAAAQGPAAAAAAAAAHMAAAAAAAKBhwAAAAAAAgHTAAAAAAAAAAAAAAAAAAIBKwAAAAAAAAAAAAAAAAACARcAAAAAAAMBgwAAAAAAAAFLAAAAAAAAAacAAAAAAANB1wAAAAAAAAAAAAAAAAAAASMAAAAAAAAAAwAAAAAAAADLAAAAAAAAAIMAAAAAAAIBJwAAAAAAAAFDAAAAAAAAAAAAAAAAAAAAwwAAAAAAAAFDAAAAAAAAAXMAAAAAAAIBdwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBdwAAAAAAAgFPAAAAAAABgaMAAAAAAAFB0wAAAAAAAAAAAAAAAAACAR8AAAAAAAAAUwAAAAAAAAD7AAAAAAACARMAAAAAAAIBVwAAAAAAAAFLAAAAAAACASsAAAAAAAEBZwAAAAAAAgFvAAAAAAAAAS8AAAAAAAIBfwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBawAAAAAAAwFnAAAAAAADAZ8AAAAAAAHBywAAAAAAAAAAAAAAAAAAAR8AAAAAAAAAswAAAAAAAAAAAAAAAAAAAP8AAAAAAAMBTwAAAAAAAAC7AAAAAAACAWsAAAAAAAOBiwAAAAAAAoGnAAAAAAADga8AAAAAAAAAAAAAAAAAAADPAAAAAAACAQcAAAAAAAMBWwAAAAAAA4GbAAAAAAADgcMAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”IE-1″:{“__ndarray__”:”AAAAAACAlEAAAAAAAIiiQAAAAAAAQIBAAAAAAAAgjEAAAAAAAAiJQAAAAAAA/JBAAAAAAADolUAAAAAAAIiUQAAAAAAARJpAAAAAAABCoEAAAAAAAAB/QAAAAAAAEIdAAAAAAAAQgkAAAAAAAJiIQAAAAAAAoI9AAAAAAABAj0AAAAAAAIyTQAAAAAAAxJdAAAAAAAAwekAAAAAAAHCCQAAAAAAAyINAAAAAAACYhEAAAAAAAFiEQAAAAAAAaIRAAAAAAABohkAAAAAAANiHQAAAAAAAwIdAAAAAAAAIh0AAAAAAAFCHQAAAAAAAUIxAAAAAAAAYgkAAAAAAANCHQAAAAAAAmI1AAAAAAABojUAAAAAAANCRQAAAAAAAHJVAAAAAAAAweUAAAAAAADCBQAAAAAAAwIJAAAAAAAAAhEAAAAAAAGCEQAAAAAAAYIVAAAAAAADwhUAAAAAAADCGQAAAAAAAgIZAAAAAAAAgiUAAAAAAANiGQAAAAAAAIItAAAAAAABwgUAAAAAAACiGQAAAAAAAEIpAAAAAAAAoi0AAAAAAAICPQAAAAAAASJJAAAAAAACAd0AAAAAAAHB/QAAAAAAAmIRAAAAAAADIh0AAAAAAABCIQAAAAAAAwIdAAAAAAABAikAAAAAAAICLQAAAAAAAMItAAAAAAADQi0AAAAAAAHiPQAAAAAAAaIJAAAAAAABghkAAAAAAAPiFQAAAAAAAYIlAAAAAAADAjEAAAAAAADSQQAAAAAAAwHdAAAAAAADQf0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”atomic mass”:[“1.00794″,”4.002602″,”6.941″,”9.012182″,”10.811″,”12.0107″,”14.0067″,”15.9994″,”18.9984032″,”20.1797″,”22.98976928″,”24.3050″,”26.9815386″,”28.0855″,”30.973762″,”32.065″,”35.453″,”39.948″,”39.0983″,”40.078″,”44.955912″,”47.867″,”50.9415″,”51.9961″,”54.938045″,”55.845″,”58.933195″,”58.6934″,”63.546″,”65.38″,”69.723″,”72.64″,”74.92160″,”78.96″,”79.904″,”83.798″,”85.4678″,”87.62″,”88.90585″,”91.224″,”92.90638″,”95.96″,”[98]”,”101.07″,”102.90550″,”106.42″,”107.8682″,”112.411″,”114.818″,”118.710″,”121.760″,”127.60″,”126.90447″,”131.293″,”132.9054519″,”137.327″,”178.49″,”180.94788″,”183.84″,”186.207″,”190.23″,”192.217″,”195.084″,”196.966569″,”200.59″,”204.3833″,”207.2″,”208.98040″,”[209]”,”[210]”,”[222]”,”[223]”,”[226]”,”[267]”,”[268]”,”[271]”,”[272]”,”[270]”,”[276]”,”[281]”,”[280]”,”[285]”,”[284]”,”[289]”,”[288]”,”[293]”,”[294]”,”[294]”],”atomic number”:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118],”atomic radius”:{“__ndarray__”:”AAAAAACAQkAAAAAAAABAQAAAAAAAwGBAAAAAAACAVkAAAAAAAIBUQAAAAAAAQFNAAAAAAADAUkAAAAAAAEBSQAAAAAAAwFFAAAAAAABAUUAAAAAAAEBjQAAAAAAAQGBAAAAAAACAXUAAAAAAAMBbQAAAAAAAgFpAAAAAAACAWUAAAAAAAMBYQAAAAAAAQFhAAAAAAACAaEAAAAAAAMBlQAAAAAAAAGJAAAAAAAAAYUAAAAAAAEBfQAAAAAAAwF9AAAAAAABgYUAAAAAAAEBfQAAAAAAAgF9AAAAAAABAXkAAAAAAAEBhQAAAAAAAYGBAAAAAAACAX0AAAAAAAIBeQAAAAAAAwF1AAAAAAAAAXUAAAAAAAIBcQAAAAAAAgFtAAAAAAABgakAAAAAAAABoQAAAAAAAQGRAAAAAAACAYkAAAAAAACBhQAAAAAAAIGJAAAAAAACAY0AAAAAAAIBfQAAAAAAA4GBAAAAAAABgYEAAAAAAACBjQAAAAAAAgGJAAAAAAAAAYkAAAAAAAKBhQAAAAAAAQGFAAAAAAADgYEAAAAAAAKBgQAAAAAAAQGBAAAAAAAAgbEAAAAAAAMBoQAAAAAAAwGJAAAAAAABAYUAAAAAAAEBiQAAAAAAA4GNAAAAAAAAAYEAAAAAAACBhQAAAAAAAAGBAAAAAAAAAYkAAAAAAAKBiQAAAAAAAgGJAAAAAAABgYkAAAAAAAEBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAACBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”boiling point”:{“__ndarray__”:”AAAAAAAANEAAAAAAAAAQQAAAAAAAPJlAAAAAAABupUAAAAAAALGwQAAAAAAAzLBAAAAAAABAU0AAAAAAAIBWQAAAAAAAQFVAAAAAAAAAO0AAAAAAABCSQAAAAAAATJVAAAAAAADQpUAAAAAAAMqoQAAAAAAAUIFAAAAAAABwhkAAAAAAAOBtQAAAAAAAwFVAAAAAAAAgkEAAAAAAAHSbQAAAAAAAPqhAAAAAAADQq0AAAAAAAMCsQAAAAAAAAKdAAAAAAAA8okAAAAAAAHyoQAAAAAAAAKlAAAAAAADkqEAAAAAAAACpQAAAAAAAcJJAAAAAAABao0AAAAAAACqoQAAAAAAAuItAAAAAAADwjUAAAAAAAMB0QAAAAAAAAF5AAAAAAAAIjkAAAAAAANyZQAAAAAAARKxAAAAAAABKskAAAAAAAJmzQAAAAAAAMLNAAAAAAAC6sUAAAAAAAEexQAAAAAAAAK9AAAAAAABIqUAAAAAAAAajQAAAAAAAQJBAAAAAAABSokAAAAAAAHamQAAAAAAAEJ1AAAAAAAC0k0AAAAAAAJB8QAAAAAAAoGRAAAAAAACAjUAAAAAAAL6gQAAAAAAADLNAAAAAAABjtkAAAAAAAMS2QAAAAAAA7bZAAAAAAACltEAAAAAAAF2yQAAAAAAAArBAAAAAAAByqEAAAAAAALCDQAAAAAAASJtAAAAAAACYn0AAAAAAALScQAAAAAAATJNAAAAAAAAA+H8AAAAAAGBqQAAAAAAAAPh/AAAAAABon0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”bonding type”:[“diatomic”,”atomic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”diatomic”,”diatomic”,”atomic”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”ca”:[0,0,118,318,0,0,0,0,106,0,0,0,0,0,0,0,0,0,0,0,52,121,81,0,38,0,212,0,0,0,452,23,0,0,0,0,0,0,52,27,59,0,0,153,153,153,0,0,28,113,34,68,0,0,0,41,27,59,0,101,153,153,153,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],”density”:{“__ndarray__”:”4yZZPRaRFz8AAAAAAAAAAEjhehSuR+E/mpmZmZmZ/T+uR+F6FK4DQBSuR+F6FAJAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAK16NwPQrvP9ejcD0K1/s/mpmZmZmZBUCkcD0K16MCQB+F61G4Hv0/XI/C9Shc/z8AAAAAAAAAAAAAAAAAAAAAhetRuB6F6z/NzMzMzMz4P+xRuB6F6wdACtejcD0KEkBxPQrXo3AYQI/C9ShcjxxA4XoUrkfhHUB7FK5H4XofQM3MzMzMzCFAUrgehevRIUDXo3A9CtchQI/C9ShcjxxAmpmZmZmZF0BI4XoUrkcVQOxRuB6F6xZASOF6FK5HE0D2KFyPwvUIQAAAAAAAAAAAexSuR+F6+D8K16NwPQoFQOF6FK5H4RFACtejcD0KGkCkcD0K1yMhQI/C9ShcjyRAAAAAAAAAJ0A9CtejcL0oQGZmZmZm5ihACtejcD0KKEB7FK5H4fokQM3MzMzMTCFAPQrXo3A9HUA9CtejcD0dQM3MzMzMzBpA9ihcj8L1GEDD9Shcj8ITQHsUrkfheoQ/FK5H4XoU/j8UrkfhehQMQB+F61G4nipAZmZmZmamMEAAAAAAAEAzQIXrUbgeBTVA16NwPQqXNkCPwvUoXI82QNejcD0KFzVAzczMzMxMM0CPwvUoXA8rQDMzMzMzsydArkfhehSuJkCPwvUoXI8jQGZmZmZmZiJAAAAAAAAA+H97FK5H4XqEPwAAAAAAAPh/AAAAAAAAFEAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronegativity”:{“__ndarray__”:”mpmZmZmZAUAAAAAAAAD4f1yPwvUoXO8/H4XrUbge+T9SuB6F61EAQGZmZmZmZgRAUrgehetRCECF61G4HoULQNejcD0K1w9AAAAAAAAA+H/D9Shcj8LtP/YoXI/C9fQ/w/UoXI/C+T9mZmZmZmb+P4XrUbgehQFApHA9CtejBEBI4XoUrkcJQAAAAAAAAPh/PQrXo3A96j8AAAAAAADwP8P1KFyPwvU/pHA9Ctej+D8UrkfhehT6P4/C9Shcj/o/zczMzMzM+D9I4XoUrkf9PxSuR+F6FP4/j8L1KFyP/j9mZmZmZmb+P2ZmZmZmZvo/9ihcj8L1/D8UrkfhehQAQHE9CtejcAFAZmZmZmZmBECuR+F6FK4HQAAAAAAAAPh/PQrXo3A96j9mZmZmZmbuP4XrUbgehfM/SOF6FK5H9T+amZmZmZn5P0jhehSuRwFAZmZmZmZm/j+amZmZmZkBQD0K16NwPQJAmpmZmZmZAUDhehSuR+H+PwrXo3A9Cvs/exSuR+F6/D9cj8L1KFz/P2ZmZmZmZgBAzczMzMzMAEBI4XoUrkcFQAAAAAAAAPh/SOF6FK5H6T97FK5H4XrsP83MzMzMzPQ/AAAAAAAA+D/hehSuR+ECQGZmZmZmZv4/mpmZmZmZAUCamZmZmZkBQD0K16NwPQJAUrgehetRBEAAAAAAAAAAQFK4HoXrUQBApHA9CtejAkApXI/C9SgAQAAAAAAAAABAmpmZmZmZAUAAAAAAAAD4f2ZmZmZmZuY/zczMzMzM7D8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronic configuration”:[“1s1″,”1s2″,”[He] 2s1″,”[He] 2s2″,”[He] 2s2 2p1″,”[He] 2s2 2p2″,”[He] 2s2 2p3″,”[He] 2s2 2p4″,”[He] 2s2 2p5″,”[He] 2s2 2p6″,”[Ne] 3s1″,”[Ne] 3s2″,”[Ne] 3s2 3p1″,”[Ne] 3s2 3p2″,”[Ne] 3s2 3p3″,”[Ne] 3s2 3p4″,”[Ne] 3s2 3p5″,”[Ne] 3s2 3p6″,”[Ar] 4s1″,”[Ar] 4s2″,”[Ar] 3d1 4s2″,”[Ar] 3d2 4s2″,”[Ar] 3d3 4s2″,”[Ar] 3d5 4s1″,”[Ar] 3d5 4s2″,”[Ar] 3d6 4s2″,”[Ar] 3d7 4s2″,”[Ar] 3d8 4s2″,”[Ar] 3d10 4s1″,”[Ar] 3d10 4s2″,”[Ar] 3d10 4s2 4p1″,”[Ar] 3d10 4s2 4p2″,”[Ar] 3d10 4s2 4p3″,”[Ar] 3d10 4s2 4p4″,”[Ar] 3d10 4s2 4p5″,”[Ar] 3d10 4s2 4p6″,”[Kr] 5s1″,”[Kr] 5s2″,”[Kr] 4d1 5s2″,”[Kr] 4d2 5s2″,”[Kr] 4d4 5s1″,”[Kr] 4d5 5s1″,”[Kr] 4d5 5s2″,”[Kr] 4d7 5s1″,”[Kr] 4d8 5s1″,”[Kr] 4d10″,”[Kr] 4d10 5s1″,”[Kr] 4d10 5s2″,”[Kr] 4d10 5s2 5p1″,”[Kr] 4d10 5s2 5p2″,”[Kr] 4d10 5s2 5p3″,”[Kr] 4d10 5s2 5p4″,”[Kr] 4d10 5s2 5p5″,”[Kr] 4d10 5s2 5p6″,”[Xe] 6s1″,”[Xe] 6s2″,”[Xe] 4f14 5d2 6s2″,”[Xe] 4f14 5d3 6s2″,”[Xe] 4f14 5d4 6s2″,”[Xe] 4f14 5d5 6s2″,”[Xe] 4f14 5d6 6s2″,”[Xe] 4f14 5d7 6s2″,”[Xe] 4f14 5d9 6s1″,”[Xe] 4f14 5d10 6s1″,”[Xe] 4f14 5d10 6s2″,”[Xe] 4f14 5d10 6s2 6p1″,”[Xe] 4f14 5d10 6s2 6p2″,”[Xe] 4f14 5d10 6s2 6p3″,”[Xe] 4f14 5d10 6s2 6p4″,”[Xe] 4f14 5d10 6s2 6p5″,”[Xe] 4f14 5d10 6s2 6p6″,”[Rn] 7s1″,”[Rn] 7s2″,”[Rn] 5f14 6d2 7s2″,”[Rn].5f14.6d3.7s2″,”[Rn].5f14.6d4.7s2″,”[Rn].5f14.6d5.7s2″,”[Rn].5f14.6d6.7s2″,”[Rn].5f14.6d7.7s2″,”[Rn].5f14.6d9.7s1″,”[Rn].5f14.6d10.7s1″,”[Rn].5f14.6d10.7s2″,”[Rn].5f14.6d10.7s2.7p1″,”[Rn].5f14.6d10.7s2.7p2″,”[Rn].5f14.6d10.7s2.7p3″,”[Rn].5f14.6d10.7s2.7p4″,”[Rn].5f14.6d10.7s2.7p5″,”[Rn].5f14.6d10.7s2.7p6″],”group”:[“1″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″],”index”:[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117],”ion radius”:[“NaN”,”NaN”,”76 (+1)”,”45 (+2)”,”27 (+3)”,”16 (+4)”,”146 (-3)”,”140 (-2)”,”133 (-1)”,”NaN”,”102 (+1)”,”72 (+2)”,”53.5 (+3)”,”40 (+4)”,”44 (+3)”,”184 (-2)”,”181 (-1)”,”NaN”,”138 (+1)”,”100 (+2)”,”74.5 (+3)”,”86 (+2)”,”79 (+2)”,”80 (+2*)”,”67 (+2)”,”78 (+2*)”,”74.5 (+2*)”,”69 (+2)”,”77 (+1)”,”74 (+2)”,”62 (+3)”,”73 (+2)”,”58 (+3)”,”198 (-2)”,”196 (-1)”,”NaN”,”152 (+1)”,”118 (+2)”,”90 (+3)”,”72 (+4)”,”72 (+3)”,”69 (+3)”,”64.5 (+4)”,”68 (+3)”,”66.5 (+3)”,”59 (+1)”,”115 (+1)”,”95 (+2)”,”80 (+3)”,”112 (+2)”,”76 (+3)”,”221 (-2)”,”220 (-1)”,”48 (+8)”,”167 (+1)”,”135 (+2)”,”71 (+4)”,”72 (+3)”,”66 (+4)”,”63 (+4)”,”63 (+4)”,”68 (+3)”,”86 (+2)”,”137 (+1)”,”119 (+1)”,”150 (+1)”,”119 (+2)”,”103 (+3)”,”94 (+4)”,”62 (+7)”,”NaN”,”180 (+1)”,”148 (+2)”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”melting point”:{“__ndarray__”:”AAAAAAAALEAAAAAAAAD4fwAAAAAAYHxAAAAAAABgmEAAAAAAAFiiQAAAAAAA3q1AAAAAAACAT0AAAAAAAIBLQAAAAAAAAEtAAAAAAAAAOUAAAAAAADB3QAAAAAAA2IxAAAAAAAAojUAAAAAAAFyaQAAAAAAA0HNAAAAAAABAeEAAAAAAAIBlQAAAAAAAAFVAAAAAAAAQdUAAAAAAAGyRQAAAAAAAWJxAAAAAAABUnkAAAAAAAA6hQAAAAAAACKFAAAAAAAC8l0AAAAAAAEycQAAAAAAAoJtAAAAAAAAAm0AAAAAAADiVQAAAAAAAqIVAAAAAAADwckAAAAAAAOySQAAAAAAACJFAAAAAAADgfkAAAAAAAKBwQAAAAAAAAF1AAAAAAACAc0AAAAAAAGiQQAAAAAAAHJxAAAAAAACgoEAAAAAAAHylQAAAAAAAoKZAAAAAAAD8okAAAAAAAF6kQAAAAAAAeqFAAAAAAACQnEAAAAAAAEyTQAAAAAAAkIJAAAAAAADgekAAAAAAAJB/QAAAAAAAQIxAAAAAAACYhkAAAAAAADB4QAAAAAAAIGRAAAAAAADgckAAAAAAAECPQAAAAAAAlKNAAAAAAAC0qUAAAAAAAN6sQAAAAAAABqtAAAAAAADUqUAAAAAAAGalQAAAAAAA5J9AAAAAAADklEAAAAAAAEBtQAAAAAAACIJAAAAAAADIgkAAAAAAAACBQAAAAAAAeIBAAAAAAAD4gUAAAAAAAEBpQAAAAAAAAPh/AAAAAABojkAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”metal”:[“nonmetal”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metalloid”,”nonmetal”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metal”,”metalloid”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metalloid”,”metalloid”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metalloid”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metal”,”halogen”,”noble gas”],”name”:[“Hydrogen”,”Helium”,”Lithium”,”Beryllium”,”Boron”,”Carbon”,”Nitrogen”,”Oxygen”,”Fluorine”,”Neon”,”Sodium”,”Magnesium”,”Aluminum”,”Silicon”,”Phosphorus”,”Sulfur”,”Chlorine”,”Argon”,”Potassium”,”Calcium”,”Scandium”,”Titanium”,”Vanadium”,”Chromium”,”Manganese”,”Iron”,”Cobalt”,”Nickel”,”Copper”,”Zinc”,”Gallium”,”Germanium”,”Arsenic”,”Selenium”,”Bromine”,”Krypton”,”Rubidium”,”Strontium”,”Yttrium”,”Zirconium”,”Niobium”,”Molybdenum”,”Technetium”,”Ruthenium”,”Rhodium”,”Palladium”,”Silver”,”Cadmium”,”Indium”,”Tin”,”Antimony”,”Tellurium”,”Iodine”,”Xenon”,”Cesium”,”Barium”,”Hafnium”,”Tantalum”,”Tungsten”,”Rhenium”,”Osmium”,”Iridium”,”Platinum”,”Gold”,”Mercury”,”Thallium”,”Lead”,”Bismuth”,”Polonium”,”Astatine”,”Radon”,”Francium”,”Radium”,”Rutherfordium”,”Dubnium”,”Seaborgium”,”Bohrium”,”Hassium”,”Meitnerium”,”Darmstadtium”,”Roentgenium”,”Copernicium”,”Nihomium”,”Flerovium”,”Moscovium”,”Livermorium”,”Tennessine”,”Oganesson”],”period”:[“I”,”I”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”],”standard state”:[“gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”symbol”:[“H”,”He”,”Li”,”Be”,”B”,”C”,”N”,”O”,”F”,”Ne”,”Na”,”Mg”,”Al”,”Si”,”P”,”S”,”Cl”,”Ar”,”K”,”Ca”,”Sc”,”Ti”,”V”,”Cr”,”Mn”,”Fe”,”Co”,”Ni”,”Cu”,”Zn”,”Ga”,”Ge”,”As”,”Se”,”Br”,”Kr”,”Rb”,”Sr”,”Y”,”Zr”,”Nb”,”Mo”,”Tc”,”Ru”,”Rh”,”Pd”,”Ag”,”Cd”,”In”,”Sn”,”Sb”,”Te”,”I”,”Xe”,”Cs”,”Ba”,”Hf”,”Ta”,”W”,”Re”,”Os”,”Ir”,”Pt”,”Au”,”Hg”,”Tl”,”Pb”,”Bi”,”Po”,”At”,”Rn”,”Fr”,”Ra”,”Rf”,”Db”,”Sg”,”Bh”,”Hs”,”Mt”,”Ds”,”Rg”,”Cn”,”Nh”,”Fl”,”Mc”,”Lv”,”Ts”,”Og”],”van der Waals radius”:{“__ndarray__”:”AAAAAAAAXkAAAAAAAIBhQAAAAAAAwGZAAAAAAAAA+H8AAAAAAAD4fwAAAAAAQGVAAAAAAABgY0AAAAAAAABjQAAAAAAAYGJAAAAAAABAY0AAAAAAAGBsQAAAAAAAoGVAAAAAAAAA+H8AAAAAAEBqQAAAAAAAgGZAAAAAAACAZkAAAAAAAOBlQAAAAAAAgGdAAAAAAAAwcUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBhQAAAAAAAYGFAAAAAAABgZ0AAAAAAAAD4fwAAAAAAIGdAAAAAAADAZ0AAAAAAACBnQAAAAAAAQGlAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBlQAAAAAAAwGNAAAAAAAAgaEAAAAAAACBrQAAAAAAAAPh/AAAAAADAaUAAAAAAAMBoQAAAAAAAAGtAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAA4GVAAAAAAADAZEAAAAAAAGBjQAAAAAAAgGhAAAAAAABAaUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”year discovered”:[“1766″,”1868″,”1817″,”1798″,”1807″,”Ancient”,”1772″,”1774″,”1670″,”1898″,”1807″,”1808″,”Ancient”,”1854″,”1669″,”Ancient”,”1774″,”1894″,”1807″,”Ancient”,”1876″,”1791″,”1803″,”Ancient”,”1774″,”Ancient”,”Ancient”,”1751″,”Ancient”,”1746″,”1875″,”1886″,”Ancient”,”1817″,”1826″,”1898″,”1861″,”1790″,”1794″,”1789″,”1801″,”1778″,”1937″,”1827″,”1803″,”1803″,”Ancient”,”1817″,”1863″,”Ancient”,”Ancient”,”1782″,”1811″,”1898″,”1860″,”1808″,”1923″,”1802″,”1783″,”1925″,”1803″,”1803″,”Ancient”,”Ancient”,”Ancient”,”1861″,”Ancient”,”Ancient”,”1898″,”1940″,”1900″,”1939″,”1898″,”1969″,”1967″,”1974″,”1976″,”1984″,”1982″,”1994″,”1994″,”1996″,”2003″,”1998″,”2003″,”2000″,”2010″,”2002″]},”selected”:{“id”:”1076″,”type”:”Selection”},”selection_policy”:{“id”:”1075″,”type”:”UnionRenderers”}},”id”:”1044″,”type”:”ColumnDataSource”},{“attributes”:{“data_source”:{“id”:”1051″,”type”:”ColumnDataSource”},”glyph”:{“id”:”1053″,”type”:”Text”},”hover_glyph”:null,”muted_glyph”:null,”nonselection_glyph”:{“id”:”1054″,”type”:”Text”},”selection_glyph”:null,”view”:{“id”:”1056″,”type”:”CDSView”}},”id”:”1055″,”type”:”GlyphRenderer”},{“attributes”:{“range”:{“id”:”1002″,”type”:”FactorRange”},”value”:-0.4},”id”:”1029″,”type”:”Dodge”},{“attributes”:{“axis_line_color”:{“value”:null},”formatter”:{“id”:”1068″,”type”:”CategoricalTickFormatter”},”major_label_standoff”:0,”major_tick_line_color”:{“value”:null},”ticker”:{“id”:”1015″,”type”:”CategoricalTicker”}},”id”:”1014″,”type”:”CategoricalAxis”},{“attributes”:{“text”:{“field”:”atomic mass”},”text_alpha”:{“value”:0.1},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”text_font_size”:{“value”:”5pt”},”x”:{“field”:”group”,”transform”:{“id”:”1029″,”type”:”Dodge”}},”y”:{“field”:”period”,”transform”:{“id”:”1050″,”type”:”Dodge”}}},”id”:”1054″,”type”:”Text”},{“attributes”:{},”id”:”1015″,”type”:”CategoricalTicker”},{“attributes”:{“source”:{“id”:”1057″,”type”:”ColumnDataSource”}},”id”:”1061″,”type”:”CDSView”},{“attributes”:{“text”:{“field”:”name”},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”text_font_size”:{“value”:”5pt”},”x”:{“field”:”group”,”transform”:{“id”:”1029″,”type”:”Dodge”}},”y”:{“field”:”period”,”transform”:{“id”:”1043″,”type”:”Dodge”}}},”id”:”1046″,”type”:”Text”},{“attributes”:{“source”:{“id”:”1023″,”type”:”ColumnDataSource”}},”id”:”1028″,”type”:”CDSView”},{“attributes”:{},”id”:”1071″,”type”:”UnionRenderers”},{“attributes”:{“dimension”:1,”grid_line_color”:null,”ticker”:{“id”:”1015″,”type”:”CategoricalTicker”}},”id”:”1017″,”type”:”Grid”},{“attributes”:{“data_source”:{“id”:”1057″,”type”:”ColumnDataSource”},”glyph”:{“id”:”1058″,”type”:”Text”},”hover_glyph”:null,”muted_glyph”:null,”nonselection_glyph”:{“id”:”1059″,”type”:”Text”},”selection_glyph”:null,”view”:{“id”:”1061″,”type”:”CDSView”}},”id”:”1060″,”type”:”GlyphRenderer”},{“attributes”:{“source”:{“id”:”1044″,”type”:”ColumnDataSource”}},”id”:”1049″,”type”:”CDSView”},{“attributes”:{},”id”:”1070″,”type”:”Selection”},{“attributes”:{},”id”:”1074″,”type”:”Selection”},{“attributes”:{“callback”:null,”renderers”:[{“id”:”1027″,”type”:”GlyphRenderer”}],”tooltips”:[[“Name”,”@name”],[“Atomic number”,”@{atomic number}”],[“Atomic mass”,”@{atomic mass}”],[“Type”,”@metal”],[“Electronic configuration”,”@{electronic configuration}”],[“Crustal abundance (ppm)”,”@ca”]]},”id”:”1018″,”type”:”HoverTool”},{“attributes”:{“data_source”:{“id”:”1023″,”type”:”ColumnDataSource”},”glyph”:{“id”:”1025″,”type”:”Rect”},”hover_glyph”:null,”muted_glyph”:null,”nonselection_glyph”:{“id”:”1026″,”type”:”Rect”},”selection_glyph”:null,”view”:{“id”:”1028″,”type”:”CDSView”}},”id”:”1027″,”type”:”GlyphRenderer”},{“attributes”:{},”id”:”1066″,”type”:”CategoricalTickFormatter”},{“attributes”:{},”id”:”1075″,”type”:”UnionRenderers”},{“attributes”:{“active_drag”:”auto”,”active_inspect”:”auto”,”active_multi”:null,”active_scroll”:”auto”,”active_tap”:”auto”,”tools”:[{“id”:”1018″,”type”:”HoverTool”}]},”id”:”1019″,”type”:”Toolbar”},{“attributes”:{},”id”:”1076″,”type”:”Selection”},{“attributes”:{“text”:{“field”:”atomic mass”},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”text_font_size”:{“value”:”5pt”},”x”:{“field”:”group”,”transform”:{“id”:”1029″,”type”:”Dodge”}},”y”:{“field”:”period”,”transform”:{“id”:”1050″,”type”:”Dodge”}}},”id”:”1053″,”type”:”Text”},{“attributes”:{“fill_alpha”:{“value”:0.1},”fill_color”:{“value”:”#1f77b4″},”height”:{“units”:”data”,”value”:0.95},”line_alpha”:{“value”:0.1},”line_color”:{“value”:”#1f77b4″},”width”:{“units”:”data”,”value”:0.95},”x”:{“field”:”group”},”y”:{“field”:”period”}},”id”:”1026″,”type”:”Rect”},{“attributes”:{“factors”:[“Sb”,”Ba”,”Be”,”Li”,”Nb”,”Ta”,”Sn”,”Ti”,”Ga”,”Co”,”Ru”,”Rh”,”Pt”,”Pd”,”Ir”,”Os”,”Mn”,”F”,”Ge”,”In”,”Ce”,”Dy”,”Er”,”Eu”,”Gd”,”Ho”,”La”,”Lu”,”Nd”,”Pr”,”Pm”,”Sm”,”Sc”,”Tb”,”Tm”,”Yb”,”Y”,”Te”,”Re”,”Zr”,”Hf”,”V”],”palette”:[“#D1C7C7″,”#BAABAB”,”#AD1F1F”,”#A65959″,”#996666″,”#996666″,”#A65959″,”#854747″,”#FF3333″,”#BF4040″,”#C27070″,”#C27070″,”#C27070″,”#C27070″,”#C27070″,”#C27070″,”#D1C7C7″,”#B87A7A”,”#E8E3E3″,”#E8E3E3″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#AD8585″,”#7A5252″,”#B87A7A”,”#E8E3E3″,”#E8E3E3″,”#C99C9C”]},”id”:”1022″,”type”:”CategoricalColorMapper”},{“attributes”:{},”id”:”1077″,”type”:”UnionRenderers”},{“attributes”:{“callback”:null,”data”:{“CPK”:[“#FFFFFF”,”#D9FFFF”,”#CC80FF”,”#C2FF00″,”#FFB5B5″,”#909090″,”#3050F8″,”#FF0D0D”,”#90E050″,”#B3E3F5″,”#AB5CF2″,”#8AFF00″,”#BFA6A6″,”#F0C8A0″,”#FF8000″,”#FFFF30″,”#1FF01F”,”#80D1E3″,”#8F40D4″,”#3DFF00″,”#E6E6E6″,”#BFC2C7″,”#A6A6AB”,”#8A99C7″,”#9C7AC7″,”#E06633″,”#F090A0″,”#50D050″,”#C88033″,”#7D80B0″,”#C28F8F”,”#668F8F”,”#BD80E3″,”#FFA100″,”#A62929″,”#5CB8D1″,”#702EB0″,”#00FF00″,”#94FFFF”,”#94E0E0″,”#73C2C9″,”#54B5B5″,”#3B9E9E”,”#248F8F”,”#0A7D8C”,”#006985″,”#C0C0C0″,”#FFD98F”,”#A67573″,”#668080″,”#9E63B5″,”#D47A00″,”#940094″,”#429EB0″,”#57178F”,”#00C900″,”#4DC2FF”,”#4DA6FF”,”#2194D6″,”#267DAB”,”#266696″,”#175487″,”#D0D0E0″,”#FFD123″,”#B8B8D0″,”#A6544D”,”#575961″,”#9E4FB5″,”#AB5C00″,”#754F45″,”#428296″,”#420066″,”#007D00″,”#CC0059″,”#D1004F”,”#D90045″,”#E00038″,”#E6002E”,”#EB0026″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″],”EA”:{“__ndarray__”:”AAAAAABAUsAAAAAAAAAAAAAAAAAAAE7AAAAAAAAAAAAAAAAAAAA7wAAAAAAAQGPAAAAAAAAAHMAAAAAAAKBhwAAAAAAAgHTAAAAAAAAAAAAAAAAAAIBKwAAAAAAAAAAAAAAAAACARcAAAAAAAMBgwAAAAAAAAFLAAAAAAAAAacAAAAAAANB1wAAAAAAAAAAAAAAAAAAASMAAAAAAAAAAwAAAAAAAADLAAAAAAAAAIMAAAAAAAIBJwAAAAAAAAFDAAAAAAAAAAAAAAAAAAAAwwAAAAAAAAFDAAAAAAAAAXMAAAAAAAIBdwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBdwAAAAAAAgFPAAAAAAABgaMAAAAAAAFB0wAAAAAAAAAAAAAAAAACAR8AAAAAAAAAUwAAAAAAAAD7AAAAAAACARMAAAAAAAIBVwAAAAAAAAFLAAAAAAACASsAAAAAAAEBZwAAAAAAAgFvAAAAAAAAAS8AAAAAAAIBfwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBawAAAAAAAwFnAAAAAAADAZ8AAAAAAAHBywAAAAAAAAAAAAAAAAAAAR8AAAAAAAAAswAAAAAAAAAAAAAAAAAAAP8AAAAAAAMBTwAAAAAAAAC7AAAAAAACAWsAAAAAAAOBiwAAAAAAAoGnAAAAAAADga8AAAAAAAAAAAAAAAAAAADPAAAAAAACAQcAAAAAAAMBWwAAAAAAA4GbAAAAAAADgcMAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”IE-1″:{“__ndarray__”:”AAAAAACAlEAAAAAAAIiiQAAAAAAAQIBAAAAAAAAgjEAAAAAAAAiJQAAAAAAA/JBAAAAAAADolUAAAAAAAIiUQAAAAAAARJpAAAAAAABCoEAAAAAAAAB/QAAAAAAAEIdAAAAAAAAQgkAAAAAAAJiIQAAAAAAAoI9AAAAAAABAj0AAAAAAAIyTQAAAAAAAxJdAAAAAAAAwekAAAAAAAHCCQAAAAAAAyINAAAAAAACYhEAAAAAAAFiEQAAAAAAAaIRAAAAAAABohkAAAAAAANiHQAAAAAAAwIdAAAAAAAAIh0AAAAAAAFCHQAAAAAAAUIxAAAAAAAAYgkAAAAAAANCHQAAAAAAAmI1AAAAAAABojUAAAAAAANCRQAAAAAAAHJVAAAAAAAAweUAAAAAAADCBQAAAAAAAwIJAAAAAAAAAhEAAAAAAAGCEQAAAAAAAYIVAAAAAAADwhUAAAAAAADCGQAAAAAAAgIZAAAAAAAAgiUAAAAAAANiGQAAAAAAAIItAAAAAAABwgUAAAAAAACiGQAAAAAAAEIpAAAAAAAAoi0AAAAAAAICPQAAAAAAASJJAAAAAAACAd0AAAAAAAHB/QAAAAAAAmIRAAAAAAADIh0AAAAAAABCIQAAAAAAAwIdAAAAAAABAikAAAAAAAICLQAAAAAAAMItAAAAAAADQi0AAAAAAAHiPQAAAAAAAaIJAAAAAAABghkAAAAAAAPiFQAAAAAAAYIlAAAAAAADAjEAAAAAAADSQQAAAAAAAwHdAAAAAAADQf0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”atomic mass”:[“1.00794″,”4.002602″,”6.941″,”9.012182″,”10.811″,”12.0107″,”14.0067″,”15.9994″,”18.9984032″,”20.1797″,”22.98976928″,”24.3050″,”26.9815386″,”28.0855″,”30.973762″,”32.065″,”35.453″,”39.948″,”39.0983″,”40.078″,”44.955912″,”47.867″,”50.9415″,”51.9961″,”54.938045″,”55.845″,”58.933195″,”58.6934″,”63.546″,”65.38″,”69.723″,”72.64″,”74.92160″,”78.96″,”79.904″,”83.798″,”85.4678″,”87.62″,”88.90585″,”91.224″,”92.90638″,”95.96″,”[98]”,”101.07″,”102.90550″,”106.42″,”107.8682″,”112.411″,”114.818″,”118.710″,”121.760″,”127.60″,”126.90447″,”131.293″,”132.9054519″,”137.327″,”178.49″,”180.94788″,”183.84″,”186.207″,”190.23″,”192.217″,”195.084″,”196.966569″,”200.59″,”204.3833″,”207.2″,”208.98040″,”[209]”,”[210]”,”[222]”,”[223]”,”[226]”,”[267]”,”[268]”,”[271]”,”[272]”,”[270]”,”[276]”,”[281]”,”[280]”,”[285]”,”[284]”,”[289]”,”[288]”,”[293]”,”[294]”,”[294]”],”atomic number”:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118],”atomic radius”:{“__ndarray__”:”AAAAAACAQkAAAAAAAABAQAAAAAAAwGBAAAAAAACAVkAAAAAAAIBUQAAAAAAAQFNAAAAAAADAUkAAAAAAAEBSQAAAAAAAwFFAAAAAAABAUUAAAAAAAEBjQAAAAAAAQGBAAAAAAACAXUAAAAAAAMBbQAAAAAAAgFpAAAAAAACAWUAAAAAAAMBYQAAAAAAAQFhAAAAAAACAaEAAAAAAAMBlQAAAAAAAAGJAAAAAAAAAYUAAAAAAAEBfQAAAAAAAwF9AAAAAAABgYUAAAAAAAEBfQAAAAAAAgF9AAAAAAABAXkAAAAAAAEBhQAAAAAAAYGBAAAAAAACAX0AAAAAAAIBeQAAAAAAAwF1AAAAAAAAAXUAAAAAAAIBcQAAAAAAAgFtAAAAAAABgakAAAAAAAABoQAAAAAAAQGRAAAAAAACAYkAAAAAAACBhQAAAAAAAIGJAAAAAAACAY0AAAAAAAIBfQAAAAAAA4GBAAAAAAABgYEAAAAAAACBjQAAAAAAAgGJAAAAAAAAAYkAAAAAAAKBhQAAAAAAAQGFAAAAAAADgYEAAAAAAAKBgQAAAAAAAQGBAAAAAAAAgbEAAAAAAAMBoQAAAAAAAwGJAAAAAAABAYUAAAAAAAEBiQAAAAAAA4GNAAAAAAAAAYEAAAAAAACBhQAAAAAAAAGBAAAAAAAAAYkAAAAAAAKBiQAAAAAAAgGJAAAAAAABgYkAAAAAAAEBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAACBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”boiling point”:{“__ndarray__”:”AAAAAAAANEAAAAAAAAAQQAAAAAAAPJlAAAAAAABupUAAAAAAALGwQAAAAAAAzLBAAAAAAABAU0AAAAAAAIBWQAAAAAAAQFVAAAAAAAAAO0AAAAAAABCSQAAAAAAATJVAAAAAAADQpUAAAAAAAMqoQAAAAAAAUIFAAAAAAABwhkAAAAAAAOBtQAAAAAAAwFVAAAAAAAAgkEAAAAAAAHSbQAAAAAAAPqhAAAAAAADQq0AAAAAAAMCsQAAAAAAAAKdAAAAAAAA8okAAAAAAAHyoQAAAAAAAAKlAAAAAAADkqEAAAAAAAACpQAAAAAAAcJJAAAAAAABao0AAAAAAACqoQAAAAAAAuItAAAAAAADwjUAAAAAAAMB0QAAAAAAAAF5AAAAAAAAIjkAAAAAAANyZQAAAAAAARKxAAAAAAABKskAAAAAAAJmzQAAAAAAAMLNAAAAAAAC6sUAAAAAAAEexQAAAAAAAAK9AAAAAAABIqUAAAAAAAAajQAAAAAAAQJBAAAAAAABSokAAAAAAAHamQAAAAAAAEJ1AAAAAAAC0k0AAAAAAAJB8QAAAAAAAoGRAAAAAAACAjUAAAAAAAL6gQAAAAAAADLNAAAAAAABjtkAAAAAAAMS2QAAAAAAA7bZAAAAAAACltEAAAAAAAF2yQAAAAAAAArBAAAAAAAByqEAAAAAAALCDQAAAAAAASJtAAAAAAACYn0AAAAAAALScQAAAAAAATJNAAAAAAAAA+H8AAAAAAGBqQAAAAAAAAPh/AAAAAABon0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”bonding type”:[“diatomic”,”atomic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”diatomic”,”diatomic”,”atomic”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”ca”:[0,0,118,318,0,0,0,0,106,0,0,0,0,0,0,0,0,0,0,0,52,121,81,0,38,0,212,0,0,0,452,23,0,0,0,0,0,0,52,27,59,0,0,153,153,153,0,0,28,113,34,68,0,0,0,41,27,59,0,101,153,153,153,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],”density”:{“__ndarray__”:”4yZZPRaRFz8AAAAAAAAAAEjhehSuR+E/mpmZmZmZ/T+uR+F6FK4DQBSuR+F6FAJAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAK16NwPQrvP9ejcD0K1/s/mpmZmZmZBUCkcD0K16MCQB+F61G4Hv0/XI/C9Shc/z8AAAAAAAAAAAAAAAAAAAAAhetRuB6F6z/NzMzMzMz4P+xRuB6F6wdACtejcD0KEkBxPQrXo3AYQI/C9ShcjxxA4XoUrkfhHUB7FK5H4XofQM3MzMzMzCFAUrgehevRIUDXo3A9CtchQI/C9ShcjxxAmpmZmZmZF0BI4XoUrkcVQOxRuB6F6xZASOF6FK5HE0D2KFyPwvUIQAAAAAAAAAAAexSuR+F6+D8K16NwPQoFQOF6FK5H4RFACtejcD0KGkCkcD0K1yMhQI/C9ShcjyRAAAAAAAAAJ0A9CtejcL0oQGZmZmZm5ihACtejcD0KKEB7FK5H4fokQM3MzMzMTCFAPQrXo3A9HUA9CtejcD0dQM3MzMzMzBpA9ihcj8L1GEDD9Shcj8ITQHsUrkfheoQ/FK5H4XoU/j8UrkfhehQMQB+F61G4nipAZmZmZmamMEAAAAAAAEAzQIXrUbgeBTVA16NwPQqXNkCPwvUoXI82QNejcD0KFzVAzczMzMxMM0CPwvUoXA8rQDMzMzMzsydArkfhehSuJkCPwvUoXI8jQGZmZmZmZiJAAAAAAAAA+H97FK5H4XqEPwAAAAAAAPh/AAAAAAAAFEAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronegativity”:{“__ndarray__”:”mpmZmZmZAUAAAAAAAAD4f1yPwvUoXO8/H4XrUbge+T9SuB6F61EAQGZmZmZmZgRAUrgehetRCECF61G4HoULQNejcD0K1w9AAAAAAAAA+H/D9Shcj8LtP/YoXI/C9fQ/w/UoXI/C+T9mZmZmZmb+P4XrUbgehQFApHA9CtejBEBI4XoUrkcJQAAAAAAAAPh/PQrXo3A96j8AAAAAAADwP8P1KFyPwvU/pHA9Ctej+D8UrkfhehT6P4/C9Shcj/o/zczMzMzM+D9I4XoUrkf9PxSuR+F6FP4/j8L1KFyP/j9mZmZmZmb+P2ZmZmZmZvo/9ihcj8L1/D8UrkfhehQAQHE9CtejcAFAZmZmZmZmBECuR+F6FK4HQAAAAAAAAPh/PQrXo3A96j9mZmZmZmbuP4XrUbgehfM/SOF6FK5H9T+amZmZmZn5P0jhehSuRwFAZmZmZmZm/j+amZmZmZkBQD0K16NwPQJAmpmZmZmZAUDhehSuR+H+PwrXo3A9Cvs/exSuR+F6/D9cj8L1KFz/P2ZmZmZmZgBAzczMzMzMAEBI4XoUrkcFQAAAAAAAAPh/SOF6FK5H6T97FK5H4XrsP83MzMzMzPQ/AAAAAAAA+D/hehSuR+ECQGZmZmZmZv4/mpmZmZmZAUCamZmZmZkBQD0K16NwPQJAUrgehetRBEAAAAAAAAAAQFK4HoXrUQBApHA9CtejAkApXI/C9SgAQAAAAAAAAABAmpmZmZmZAUAAAAAAAAD4f2ZmZmZmZuY/zczMzMzM7D8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronic configuration”:[“1s1″,”1s2″,”[He] 2s1″,”[He] 2s2″,”[He] 2s2 2p1″,”[He] 2s2 2p2″,”[He] 2s2 2p3″,”[He] 2s2 2p4″,”[He] 2s2 2p5″,”[He] 2s2 2p6″,”[Ne] 3s1″,”[Ne] 3s2″,”[Ne] 3s2 3p1″,”[Ne] 3s2 3p2″,”[Ne] 3s2 3p3″,”[Ne] 3s2 3p4″,”[Ne] 3s2 3p5″,”[Ne] 3s2 3p6″,”[Ar] 4s1″,”[Ar] 4s2″,”[Ar] 3d1 4s2″,”[Ar] 3d2 4s2″,”[Ar] 3d3 4s2″,”[Ar] 3d5 4s1″,”[Ar] 3d5 4s2″,”[Ar] 3d6 4s2″,”[Ar] 3d7 4s2″,”[Ar] 3d8 4s2″,”[Ar] 3d10 4s1″,”[Ar] 3d10 4s2″,”[Ar] 3d10 4s2 4p1″,”[Ar] 3d10 4s2 4p2″,”[Ar] 3d10 4s2 4p3″,”[Ar] 3d10 4s2 4p4″,”[Ar] 3d10 4s2 4p5″,”[Ar] 3d10 4s2 4p6″,”[Kr] 5s1″,”[Kr] 5s2″,”[Kr] 4d1 5s2″,”[Kr] 4d2 5s2″,”[Kr] 4d4 5s1″,”[Kr] 4d5 5s1″,”[Kr] 4d5 5s2″,”[Kr] 4d7 5s1″,”[Kr] 4d8 5s1″,”[Kr] 4d10″,”[Kr] 4d10 5s1″,”[Kr] 4d10 5s2″,”[Kr] 4d10 5s2 5p1″,”[Kr] 4d10 5s2 5p2″,”[Kr] 4d10 5s2 5p3″,”[Kr] 4d10 5s2 5p4″,”[Kr] 4d10 5s2 5p5″,”[Kr] 4d10 5s2 5p6″,”[Xe] 6s1″,”[Xe] 6s2″,”[Xe] 4f14 5d2 6s2″,”[Xe] 4f14 5d3 6s2″,”[Xe] 4f14 5d4 6s2″,”[Xe] 4f14 5d5 6s2″,”[Xe] 4f14 5d6 6s2″,”[Xe] 4f14 5d7 6s2″,”[Xe] 4f14 5d9 6s1″,”[Xe] 4f14 5d10 6s1″,”[Xe] 4f14 5d10 6s2″,”[Xe] 4f14 5d10 6s2 6p1″,”[Xe] 4f14 5d10 6s2 6p2″,”[Xe] 4f14 5d10 6s2 6p3″,”[Xe] 4f14 5d10 6s2 6p4″,”[Xe] 4f14 5d10 6s2 6p5″,”[Xe] 4f14 5d10 6s2 6p6″,”[Rn] 7s1″,”[Rn] 7s2″,”[Rn] 5f14 6d2 7s2″,”[Rn].5f14.6d3.7s2″,”[Rn].5f14.6d4.7s2″,”[Rn].5f14.6d5.7s2″,”[Rn].5f14.6d6.7s2″,”[Rn].5f14.6d7.7s2″,”[Rn].5f14.6d9.7s1″,”[Rn].5f14.6d10.7s1″,”[Rn].5f14.6d10.7s2″,”[Rn].5f14.6d10.7s2.7p1″,”[Rn].5f14.6d10.7s2.7p2″,”[Rn].5f14.6d10.7s2.7p3″,”[Rn].5f14.6d10.7s2.7p4″,”[Rn].5f14.6d10.7s2.7p5″,”[Rn].5f14.6d10.7s2.7p6″],”group”:[“1″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″],”index”:[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117],”ion radius”:[“NaN”,”NaN”,”76 (+1)”,”45 (+2)”,”27 (+3)”,”16 (+4)”,”146 (-3)”,”140 (-2)”,”133 (-1)”,”NaN”,”102 (+1)”,”72 (+2)”,”53.5 (+3)”,”40 (+4)”,”44 (+3)”,”184 (-2)”,”181 (-1)”,”NaN”,”138 (+1)”,”100 (+2)”,”74.5 (+3)”,”86 (+2)”,”79 (+2)”,”80 (+2*)”,”67 (+2)”,”78 (+2*)”,”74.5 (+2*)”,”69 (+2)”,”77 (+1)”,”74 (+2)”,”62 (+3)”,”73 (+2)”,”58 (+3)”,”198 (-2)”,”196 (-1)”,”NaN”,”152 (+1)”,”118 (+2)”,”90 (+3)”,”72 (+4)”,”72 (+3)”,”69 (+3)”,”64.5 (+4)”,”68 (+3)”,”66.5 (+3)”,”59 (+1)”,”115 (+1)”,”95 (+2)”,”80 (+3)”,”112 (+2)”,”76 (+3)”,”221 (-2)”,”220 (-1)”,”48 (+8)”,”167 (+1)”,”135 (+2)”,”71 (+4)”,”72 (+3)”,”66 (+4)”,”63 (+4)”,”63 (+4)”,”68 (+3)”,”86 (+2)”,”137 (+1)”,”119 (+1)”,”150 (+1)”,”119 (+2)”,”103 (+3)”,”94 (+4)”,”62 (+7)”,”NaN”,”180 (+1)”,”148 (+2)”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”melting point”:{“__ndarray__”:”AAAAAAAALEAAAAAAAAD4fwAAAAAAYHxAAAAAAABgmEAAAAAAAFiiQAAAAAAA3q1AAAAAAACAT0AAAAAAAIBLQAAAAAAAAEtAAAAAAAAAOUAAAAAAADB3QAAAAAAA2IxAAAAAAAAojUAAAAAAAFyaQAAAAAAA0HNAAAAAAABAeEAAAAAAAIBlQAAAAAAAAFVAAAAAAAAQdUAAAAAAAGyRQAAAAAAAWJxAAAAAAABUnkAAAAAAAA6hQAAAAAAACKFAAAAAAAC8l0AAAAAAAEycQAAAAAAAoJtAAAAAAAAAm0AAAAAAADiVQAAAAAAAqIVAAAAAAADwckAAAAAAAOySQAAAAAAACJFAAAAAAADgfkAAAAAAAKBwQAAAAAAAAF1AAAAAAACAc0AAAAAAAGiQQAAAAAAAHJxAAAAAAACgoEAAAAAAAHylQAAAAAAAoKZAAAAAAAD8okAAAAAAAF6kQAAAAAAAeqFAAAAAAACQnEAAAAAAAEyTQAAAAAAAkIJAAAAAAADgekAAAAAAAJB/QAAAAAAAQIxAAAAAAACYhkAAAAAAADB4QAAAAAAAIGRAAAAAAADgckAAAAAAAECPQAAAAAAAlKNAAAAAAAC0qUAAAAAAAN6sQAAAAAAABqtAAAAAAADUqUAAAAAAAGalQAAAAAAA5J9AAAAAAADklEAAAAAAAEBtQAAAAAAACIJAAAAAAADIgkAAAAAAAACBQAAAAAAAeIBAAAAAAAD4gUAAAAAAAEBpQAAAAAAAAPh/AAAAAABojkAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”metal”:[“nonmetal”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metalloid”,”nonmetal”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metal”,”metalloid”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metalloid”,”metalloid”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metalloid”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metal”,”halogen”,”noble gas”],”name”:[“Hydrogen”,”Helium”,”Lithium”,”Beryllium”,”Boron”,”Carbon”,”Nitrogen”,”Oxygen”,”Fluorine”,”Neon”,”Sodium”,”Magnesium”,”Aluminum”,”Silicon”,”Phosphorus”,”Sulfur”,”Chlorine”,”Argon”,”Potassium”,”Calcium”,”Scandium”,”Titanium”,”Vanadium”,”Chromium”,”Manganese”,”Iron”,”Cobalt”,”Nickel”,”Copper”,”Zinc”,”Gallium”,”Germanium”,”Arsenic”,”Selenium”,”Bromine”,”Krypton”,”Rubidium”,”Strontium”,”Yttrium”,”Zirconium”,”Niobium”,”Molybdenum”,”Technetium”,”Ruthenium”,”Rhodium”,”Palladium”,”Silver”,”Cadmium”,”Indium”,”Tin”,”Antimony”,”Tellurium”,”Iodine”,”Xenon”,”Cesium”,”Barium”,”Hafnium”,”Tantalum”,”Tungsten”,”Rhenium”,”Osmium”,”Iridium”,”Platinum”,”Gold”,”Mercury”,”Thallium”,”Lead”,”Bismuth”,”Polonium”,”Astatine”,”Radon”,”Francium”,”Radium”,”Rutherfordium”,”Dubnium”,”Seaborgium”,”Bohrium”,”Hassium”,”Meitnerium”,”Darmstadtium”,”Roentgenium”,”Copernicium”,”Nihomium”,”Flerovium”,”Moscovium”,”Livermorium”,”Tennessine”,”Oganesson”],”period”:[“I”,”I”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”],”standard state”:[“gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”symbol”:[“H”,”He”,”Li”,”Be”,”B”,”C”,”N”,”O”,”F”,”Ne”,”Na”,”Mg”,”Al”,”Si”,”P”,”S”,”Cl”,”Ar”,”K”,”Ca”,”Sc”,”Ti”,”V”,”Cr”,”Mn”,”Fe”,”Co”,”Ni”,”Cu”,”Zn”,”Ga”,”Ge”,”As”,”Se”,”Br”,”Kr”,”Rb”,”Sr”,”Y”,”Zr”,”Nb”,”Mo”,”Tc”,”Ru”,”Rh”,”Pd”,”Ag”,”Cd”,”In”,”Sn”,”Sb”,”Te”,”I”,”Xe”,”Cs”,”Ba”,”Hf”,”Ta”,”W”,”Re”,”Os”,”Ir”,”Pt”,”Au”,”Hg”,”Tl”,”Pb”,”Bi”,”Po”,”At”,”Rn”,”Fr”,”Ra”,”Rf”,”Db”,”Sg”,”Bh”,”Hs”,”Mt”,”Ds”,”Rg”,”Cn”,”Nh”,”Fl”,”Mc”,”Lv”,”Ts”,”Og”],”van der Waals radius”:{“__ndarray__”:”AAAAAAAAXkAAAAAAAIBhQAAAAAAAwGZAAAAAAAAA+H8AAAAAAAD4fwAAAAAAQGVAAAAAAABgY0AAAAAAAABjQAAAAAAAYGJAAAAAAABAY0AAAAAAAGBsQAAAAAAAoGVAAAAAAAAA+H8AAAAAAEBqQAAAAAAAgGZAAAAAAACAZkAAAAAAAOBlQAAAAAAAgGdAAAAAAAAwcUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBhQAAAAAAAYGFAAAAAAABgZ0AAAAAAAAD4fwAAAAAAIGdAAAAAAADAZ0AAAAAAACBnQAAAAAAAQGlAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBlQAAAAAAAwGNAAAAAAAAgaEAAAAAAACBrQAAAAAAAAPh/AAAAAADAaUAAAAAAAMBoQAAAAAAAAGtAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAA4GVAAAAAAADAZEAAAAAAAGBjQAAAAAAAgGhAAAAAAABAaUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”year discovered”:[“1766″,”1868″,”1817″,”1798″,”1807″,”Ancient”,”1772″,”1774″,”1670″,”1898″,”1807″,”1808″,”Ancient”,”1854″,”1669″,”Ancient”,”1774″,”1894″,”1807″,”Ancient”,”1876″,”1791″,”1803″,”Ancient”,”1774″,”Ancient”,”Ancient”,”1751″,”Ancient”,”1746″,”1875″,”1886″,”Ancient”,”1817″,”1826″,”1898″,”1861″,”1790″,”1794″,”1789″,”1801″,”1778″,”1937″,”1827″,”1803″,”1803″,”Ancient”,”1817″,”1863″,”Ancient”,”Ancient”,”1782″,”1811″,”1898″,”1860″,”1808″,”1923″,”1802″,”1783″,”1925″,”1803″,”1803″,”Ancient”,”Ancient”,”Ancient”,”1861″,”Ancient”,”Ancient”,”1898″,”1940″,”1900″,”1939″,”1898″,”1969″,”1967″,”1974″,”1976″,”1984″,”1982″,”1994″,”1994″,”1996″,”2003″,”1998″,”2003″,”2000″,”2010″,”2002″]},”selected”:{“id”:”1070″,”type”:”Selection”},”selection_policy”:{“id”:”1069″,”type”:”UnionRenderers”}},”id”:”1023″,”type”:”ColumnDataSource”},{“attributes”:{“text”:””,”text_font_size”:{“value”:”36pt”}},”id”:”1021″,”type”:”Title”},{“attributes”:{},”id”:”1078″,”type”:”Selection”},{“attributes”:{“source”:{“id”:”1030″,”type”:”ColumnDataSource”}},”id”:”1035″,”type”:”CDSView”},{“attributes”:{“below”:[{“id”:”1010″,”type”:”CategoricalAxis”}],”center”:[{“id”:”1013″,”type”:”Grid”},{“id”:”1017″,”type”:”Grid”}],”left”:[{“id”:”1014″,”type”:”CategoricalAxis”}],”outline_line_color”:{“value”:null},”plot_height”:450,”plot_width”:1000,”renderers”:[{“id”:”1027″,”type”:”GlyphRenderer”},{“id”:”1034″,”type”:”GlyphRenderer”},{“id”:”1041″,”type”:”GlyphRenderer”},{“id”:”1048″,”type”:”GlyphRenderer”},{“id”:”1055″,”type”:”GlyphRenderer”},{“id”:”1060″,”type”:”GlyphRenderer”}],”title”:{“id”:”1021″,”type”:”Title”},”toolbar”:{“id”:”1019″,”type”:”Toolbar”},”toolbar_location”:null,”x_range”:{“id”:”1002″,”type”:”FactorRange”},”x_scale”:{“id”:”1006″,”type”:”CategoricalScale”},”y_range”:{“id”:”1004″,”type”:”FactorRange”},”y_scale”:{“id”:”1008″,”type”:”CategoricalScale”}},”id”:”1001″,”subtype”:”Figure”,”type”:”Plot”},{“attributes”:{“callback”:null,”data”:{“CPK”:[“#FFFFFF”,”#D9FFFF”,”#CC80FF”,”#C2FF00″,”#FFB5B5″,”#909090″,”#3050F8″,”#FF0D0D”,”#90E050″,”#B3E3F5″,”#AB5CF2″,”#8AFF00″,”#BFA6A6″,”#F0C8A0″,”#FF8000″,”#FFFF30″,”#1FF01F”,”#80D1E3″,”#8F40D4″,”#3DFF00″,”#E6E6E6″,”#BFC2C7″,”#A6A6AB”,”#8A99C7″,”#9C7AC7″,”#E06633″,”#F090A0″,”#50D050″,”#C88033″,”#7D80B0″,”#C28F8F”,”#668F8F”,”#BD80E3″,”#FFA100″,”#A62929″,”#5CB8D1″,”#702EB0″,”#00FF00″,”#94FFFF”,”#94E0E0″,”#73C2C9″,”#54B5B5″,”#3B9E9E”,”#248F8F”,”#0A7D8C”,”#006985″,”#C0C0C0″,”#FFD98F”,”#A67573″,”#668080″,”#9E63B5″,”#D47A00″,”#940094″,”#429EB0″,”#57178F”,”#00C900″,”#4DC2FF”,”#4DA6FF”,”#2194D6″,”#267DAB”,”#266696″,”#175487″,”#D0D0E0″,”#FFD123″,”#B8B8D0″,”#A6544D”,”#575961″,”#9E4FB5″,”#AB5C00″,”#754F45″,”#428296″,”#420066″,”#007D00″,”#CC0059″,”#D1004F”,”#D90045″,”#E00038″,”#E6002E”,”#EB0026″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″],”EA”:{“__ndarray__”:”AAAAAABAUsAAAAAAAAAAAAAAAAAAAE7AAAAAAAAAAAAAAAAAAAA7wAAAAAAAQGPAAAAAAAAAHMAAAAAAAKBhwAAAAAAAgHTAAAAAAAAAAAAAAAAAAIBKwAAAAAAAAAAAAAAAAACARcAAAAAAAMBgwAAAAAAAAFLAAAAAAAAAacAAAAAAANB1wAAAAAAAAAAAAAAAAAAASMAAAAAAAAAAwAAAAAAAADLAAAAAAAAAIMAAAAAAAIBJwAAAAAAAAFDAAAAAAAAAAAAAAAAAAAAwwAAAAAAAAFDAAAAAAAAAXMAAAAAAAIBdwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBdwAAAAAAAgFPAAAAAAABgaMAAAAAAAFB0wAAAAAAAAAAAAAAAAACAR8AAAAAAAAAUwAAAAAAAAD7AAAAAAACARMAAAAAAAIBVwAAAAAAAAFLAAAAAAACASsAAAAAAAEBZwAAAAAAAgFvAAAAAAAAAS8AAAAAAAIBfwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBawAAAAAAAwFnAAAAAAADAZ8AAAAAAAHBywAAAAAAAAAAAAAAAAAAAR8AAAAAAAAAswAAAAAAAAAAAAAAAAAAAP8AAAAAAAMBTwAAAAAAAAC7AAAAAAACAWsAAAAAAAOBiwAAAAAAAoGnAAAAAAADga8AAAAAAAAAAAAAAAAAAADPAAAAAAACAQcAAAAAAAMBWwAAAAAAA4GbAAAAAAADgcMAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”IE-1″:{“__ndarray__”:”AAAAAACAlEAAAAAAAIiiQAAAAAAAQIBAAAAAAAAgjEAAAAAAAAiJQAAAAAAA/JBAAAAAAADolUAAAAAAAIiUQAAAAAAARJpAAAAAAABCoEAAAAAAAAB/QAAAAAAAEIdAAAAAAAAQgkAAAAAAAJiIQAAAAAAAoI9AAAAAAABAj0AAAAAAAIyTQAAAAAAAxJdAAAAAAAAwekAAAAAAAHCCQAAAAAAAyINAAAAAAACYhEAAAAAAAFiEQAAAAAAAaIRAAAAAAABohkAAAAAAANiHQAAAAAAAwIdAAAAAAAAIh0AAAAAAAFCHQAAAAAAAUIxAAAAAAAAYgkAAAAAAANCHQAAAAAAAmI1AAAAAAABojUAAAAAAANCRQAAAAAAAHJVAAAAAAAAweUAAAAAAADCBQAAAAAAAwIJAAAAAAAAAhEAAAAAAAGCEQAAAAAAAYIVAAAAAAADwhUAAAAAAADCGQAAAAAAAgIZAAAAAAAAgiUAAAAAAANiGQAAAAAAAIItAAAAAAABwgUAAAAAAACiGQAAAAAAAEIpAAAAAAAAoi0AAAAAAAICPQAAAAAAASJJAAAAAAACAd0AAAAAAAHB/QAAAAAAAmIRAAAAAAADIh0AAAAAAABCIQAAAAAAAwIdAAAAAAABAikAAAAAAAICLQAAAAAAAMItAAAAAAADQi0AAAAAAAHiPQAAAAAAAaIJAAAAAAABghkAAAAAAAPiFQAAAAAAAYIlAAAAAAADAjEAAAAAAADSQQAAAAAAAwHdAAAAAAADQf0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”atomic mass”:[“1.00794″,”4.002602″,”6.941″,”9.012182″,”10.811″,”12.0107″,”14.0067″,”15.9994″,”18.9984032″,”20.1797″,”22.98976928″,”24.3050″,”26.9815386″,”28.0855″,”30.973762″,”32.065″,”35.453″,”39.948″,”39.0983″,”40.078″,”44.955912″,”47.867″,”50.9415″,”51.9961″,”54.938045″,”55.845″,”58.933195″,”58.6934″,”63.546″,”65.38″,”69.723″,”72.64″,”74.92160″,”78.96″,”79.904″,”83.798″,”85.4678″,”87.62″,”88.90585″,”91.224″,”92.90638″,”95.96″,”[98]”,”101.07″,”102.90550″,”106.42″,”107.8682″,”112.411″,”114.818″,”118.710″,”121.760″,”127.60″,”126.90447″,”131.293″,”132.9054519″,”137.327″,”178.49″,”180.94788″,”183.84″,”186.207″,”190.23″,”192.217″,”195.084″,”196.966569″,”200.59″,”204.3833″,”207.2″,”208.98040″,”[209]”,”[210]”,”[222]”,”[223]”,”[226]”,”[267]”,”[268]”,”[271]”,”[272]”,”[270]”,”[276]”,”[281]”,”[280]”,”[285]”,”[284]”,”[289]”,”[288]”,”[293]”,”[294]”,”[294]”],”atomic number”:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118],”atomic radius”:{“__ndarray__”:”AAAAAACAQkAAAAAAAABAQAAAAAAAwGBAAAAAAACAVkAAAAAAAIBUQAAAAAAAQFNAAAAAAADAUkAAAAAAAEBSQAAAAAAAwFFAAAAAAABAUUAAAAAAAEBjQAAAAAAAQGBAAAAAAACAXUAAAAAAAMBbQAAAAAAAgFpAAAAAAACAWUAAAAAAAMBYQAAAAAAAQFhAAAAAAACAaEAAAAAAAMBlQAAAAAAAAGJAAAAAAAAAYUAAAAAAAEBfQAAAAAAAwF9AAAAAAABgYUAAAAAAAEBfQAAAAAAAgF9AAAAAAABAXkAAAAAAAEBhQAAAAAAAYGBAAAAAAACAX0AAAAAAAIBeQAAAAAAAwF1AAAAAAAAAXUAAAAAAAIBcQAAAAAAAgFtAAAAAAABgakAAAAAAAABoQAAAAAAAQGRAAAAAAACAYkAAAAAAACBhQAAAAAAAIGJAAAAAAACAY0AAAAAAAIBfQAAAAAAA4GBAAAAAAABgYEAAAAAAACBjQAAAAAAAgGJAAAAAAAAAYkAAAAAAAKBhQAAAAAAAQGFAAAAAAADgYEAAAAAAAKBgQAAAAAAAQGBAAAAAAAAgbEAAAAAAAMBoQAAAAAAAwGJAAAAAAABAYUAAAAAAAEBiQAAAAAAA4GNAAAAAAAAAYEAAAAAAACBhQAAAAAAAAGBAAAAAAAAAYkAAAAAAAKBiQAAAAAAAgGJAAAAAAABgYkAAAAAAAEBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAACBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”boiling point”:{“__ndarray__”:”AAAAAAAANEAAAAAAAAAQQAAAAAAAPJlAAAAAAABupUAAAAAAALGwQAAAAAAAzLBAAAAAAABAU0AAAAAAAIBWQAAAAAAAQFVAAAAAAAAAO0AAAAAAABCSQAAAAAAATJVAAAAAAADQpUAAAAAAAMqoQAAAAAAAUIFAAAAAAABwhkAAAAAAAOBtQAAAAAAAwFVAAAAAAAAgkEAAAAAAAHSbQAAAAAAAPqhAAAAAAADQq0AAAAAAAMCsQAAAAAAAAKdAAAAAAAA8okAAAAAAAHyoQAAAAAAAAKlAAAAAAADkqEAAAAAAAACpQAAAAAAAcJJAAAAAAABao0AAAAAAACqoQAAAAAAAuItAAAAAAADwjUAAAAAAAMB0QAAAAAAAAF5AAAAAAAAIjkAAAAAAANyZQAAAAAAARKxAAAAAAABKskAAAAAAAJmzQAAAAAAAMLNAAAAAAAC6sUAAAAAAAEexQAAAAAAAAK9AAAAAAABIqUAAAAAAAAajQAAAAAAAQJBAAAAAAABSokAAAAAAAHamQAAAAAAAEJ1AAAAAAAC0k0AAAAAAAJB8QAAAAAAAoGRAAAAAAACAjUAAAAAAAL6gQAAAAAAADLNAAAAAAABjtkAAAAAAAMS2QAAAAAAA7bZAAAAAAACltEAAAAAAAF2yQAAAAAAAArBAAAAAAAByqEAAAAAAALCDQAAAAAAASJtAAAAAAACYn0AAAAAAALScQAAAAAAATJNAAAAAAAAA+H8AAAAAAGBqQAAAAAAAAPh/AAAAAABon0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”bonding type”:[“diatomic”,”atomic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”diatomic”,”diatomic”,”atomic”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”ca”:[0,0,118,318,0,0,0,0,106,0,0,0,0,0,0,0,0,0,0,0,52,121,81,0,38,0,212,0,0,0,452,23,0,0,0,0,0,0,52,27,59,0,0,153,153,153,0,0,28,113,34,68,0,0,0,41,27,59,0,101,153,153,153,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],”density”:{“__ndarray__”:”4yZZPRaRFz8AAAAAAAAAAEjhehSuR+E/mpmZmZmZ/T+uR+F6FK4DQBSuR+F6FAJAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAK16NwPQrvP9ejcD0K1/s/mpmZmZmZBUCkcD0K16MCQB+F61G4Hv0/XI/C9Shc/z8AAAAAAAAAAAAAAAAAAAAAhetRuB6F6z/NzMzMzMz4P+xRuB6F6wdACtejcD0KEkBxPQrXo3AYQI/C9ShcjxxA4XoUrkfhHUB7FK5H4XofQM3MzMzMzCFAUrgehevRIUDXo3A9CtchQI/C9ShcjxxAmpmZmZmZF0BI4XoUrkcVQOxRuB6F6xZASOF6FK5HE0D2KFyPwvUIQAAAAAAAAAAAexSuR+F6+D8K16NwPQoFQOF6FK5H4RFACtejcD0KGkCkcD0K1yMhQI/C9ShcjyRAAAAAAAAAJ0A9CtejcL0oQGZmZmZm5ihACtejcD0KKEB7FK5H4fokQM3MzMzMTCFAPQrXo3A9HUA9CtejcD0dQM3MzMzMzBpA9ihcj8L1GEDD9Shcj8ITQHsUrkfheoQ/FK5H4XoU/j8UrkfhehQMQB+F61G4nipAZmZmZmamMEAAAAAAAEAzQIXrUbgeBTVA16NwPQqXNkCPwvUoXI82QNejcD0KFzVAzczMzMxMM0CPwvUoXA8rQDMzMzMzsydArkfhehSuJkCPwvUoXI8jQGZmZmZmZiJAAAAAAAAA+H97FK5H4XqEPwAAAAAAAPh/AAAAAAAAFEAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronegativity”:{“__ndarray__”:”mpmZmZmZAUAAAAAAAAD4f1yPwvUoXO8/H4XrUbge+T9SuB6F61EAQGZmZmZmZgRAUrgehetRCECF61G4HoULQNejcD0K1w9AAAAAAAAA+H/D9Shcj8LtP/YoXI/C9fQ/w/UoXI/C+T9mZmZmZmb+P4XrUbgehQFApHA9CtejBEBI4XoUrkcJQAAAAAAAAPh/PQrXo3A96j8AAAAAAADwP8P1KFyPwvU/pHA9Ctej+D8UrkfhehT6P4/C9Shcj/o/zczMzMzM+D9I4XoUrkf9PxSuR+F6FP4/j8L1KFyP/j9mZmZmZmb+P2ZmZmZmZvo/9ihcj8L1/D8UrkfhehQAQHE9CtejcAFAZmZmZmZmBECuR+F6FK4HQAAAAAAAAPh/PQrXo3A96j9mZmZmZmbuP4XrUbgehfM/SOF6FK5H9T+amZmZmZn5P0jhehSuRwFAZmZmZmZm/j+amZmZmZkBQD0K16NwPQJAmpmZmZmZAUDhehSuR+H+PwrXo3A9Cvs/exSuR+F6/D9cj8L1KFz/P2ZmZmZmZgBAzczMzMzMAEBI4XoUrkcFQAAAAAAAAPh/SOF6FK5H6T97FK5H4XrsP83MzMzMzPQ/AAAAAAAA+D/hehSuR+ECQGZmZmZmZv4/mpmZmZmZAUCamZmZmZkBQD0K16NwPQJAUrgehetRBEAAAAAAAAAAQFK4HoXrUQBApHA9CtejAkApXI/C9SgAQAAAAAAAAABAmpmZmZmZAUAAAAAAAAD4f2ZmZmZmZuY/zczMzMzM7D8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronic configuration”:[“1s1″,”1s2″,”[He] 2s1″,”[He] 2s2″,”[He] 2s2 2p1″,”[He] 2s2 2p2″,”[He] 2s2 2p3″,”[He] 2s2 2p4″,”[He] 2s2 2p5″,”[He] 2s2 2p6″,”[Ne] 3s1″,”[Ne] 3s2″,”[Ne] 3s2 3p1″,”[Ne] 3s2 3p2″,”[Ne] 3s2 3p3″,”[Ne] 3s2 3p4″,”[Ne] 3s2 3p5″,”[Ne] 3s2 3p6″,”[Ar] 4s1″,”[Ar] 4s2″,”[Ar] 3d1 4s2″,”[Ar] 3d2 4s2″,”[Ar] 3d3 4s2″,”[Ar] 3d5 4s1″,”[Ar] 3d5 4s2″,”[Ar] 3d6 4s2″,”[Ar] 3d7 4s2″,”[Ar] 3d8 4s2″,”[Ar] 3d10 4s1″,”[Ar] 3d10 4s2″,”[Ar] 3d10 4s2 4p1″,”[Ar] 3d10 4s2 4p2″,”[Ar] 3d10 4s2 4p3″,”[Ar] 3d10 4s2 4p4″,”[Ar] 3d10 4s2 4p5″,”[Ar] 3d10 4s2 4p6″,”[Kr] 5s1″,”[Kr] 5s2″,”[Kr] 4d1 5s2″,”[Kr] 4d2 5s2″,”[Kr] 4d4 5s1″,”[Kr] 4d5 5s1″,”[Kr] 4d5 5s2″,”[Kr] 4d7 5s1″,”[Kr] 4d8 5s1″,”[Kr] 4d10″,”[Kr] 4d10 5s1″,”[Kr] 4d10 5s2″,”[Kr] 4d10 5s2 5p1″,”[Kr] 4d10 5s2 5p2″,”[Kr] 4d10 5s2 5p3″,”[Kr] 4d10 5s2 5p4″,”[Kr] 4d10 5s2 5p5″,”[Kr] 4d10 5s2 5p6″,”[Xe] 6s1″,”[Xe] 6s2″,”[Xe] 4f14 5d2 6s2″,”[Xe] 4f14 5d3 6s2″,”[Xe] 4f14 5d4 6s2″,”[Xe] 4f14 5d5 6s2″,”[Xe] 4f14 5d6 6s2″,”[Xe] 4f14 5d7 6s2″,”[Xe] 4f14 5d9 6s1″,”[Xe] 4f14 5d10 6s1″,”[Xe] 4f14 5d10 6s2″,”[Xe] 4f14 5d10 6s2 6p1″,”[Xe] 4f14 5d10 6s2 6p2″,”[Xe] 4f14 5d10 6s2 6p3″,”[Xe] 4f14 5d10 6s2 6p4″,”[Xe] 4f14 5d10 6s2 6p5″,”[Xe] 4f14 5d10 6s2 6p6″,”[Rn] 7s1″,”[Rn] 7s2″,”[Rn] 5f14 6d2 7s2″,”[Rn].5f14.6d3.7s2″,”[Rn].5f14.6d4.7s2″,”[Rn].5f14.6d5.7s2″,”[Rn].5f14.6d6.7s2″,”[Rn].5f14.6d7.7s2″,”[Rn].5f14.6d9.7s1″,”[Rn].5f14.6d10.7s1″,”[Rn].5f14.6d10.7s2″,”[Rn].5f14.6d10.7s2.7p1″,”[Rn].5f14.6d10.7s2.7p2″,”[Rn].5f14.6d10.7s2.7p3″,”[Rn].5f14.6d10.7s2.7p4″,”[Rn].5f14.6d10.7s2.7p5″,”[Rn].5f14.6d10.7s2.7p6″],”group”:[“1″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″],”index”:[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117],”ion radius”:[“NaN”,”NaN”,”76 (+1)”,”45 (+2)”,”27 (+3)”,”16 (+4)”,”146 (-3)”,”140 (-2)”,”133 (-1)”,”NaN”,”102 (+1)”,”72 (+2)”,”53.5 (+3)”,”40 (+4)”,”44 (+3)”,”184 (-2)”,”181 (-1)”,”NaN”,”138 (+1)”,”100 (+2)”,”74.5 (+3)”,”86 (+2)”,”79 (+2)”,”80 (+2*)”,”67 (+2)”,”78 (+2*)”,”74.5 (+2*)”,”69 (+2)”,”77 (+1)”,”74 (+2)”,”62 (+3)”,”73 (+2)”,”58 (+3)”,”198 (-2)”,”196 (-1)”,”NaN”,”152 (+1)”,”118 (+2)”,”90 (+3)”,”72 (+4)”,”72 (+3)”,”69 (+3)”,”64.5 (+4)”,”68 (+3)”,”66.5 (+3)”,”59 (+1)”,”115 (+1)”,”95 (+2)”,”80 (+3)”,”112 (+2)”,”76 (+3)”,”221 (-2)”,”220 (-1)”,”48 (+8)”,”167 (+1)”,”135 (+2)”,”71 (+4)”,”72 (+3)”,”66 (+4)”,”63 (+4)”,”63 (+4)”,”68 (+3)”,”86 (+2)”,”137 (+1)”,”119 (+1)”,”150 (+1)”,”119 (+2)”,”103 (+3)”,”94 (+4)”,”62 (+7)”,”NaN”,”180 (+1)”,”148 (+2)”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”melting point”:{“__ndarray__”:”AAAAAAAALEAAAAAAAAD4fwAAAAAAYHxAAAAAAABgmEAAAAAAAFiiQAAAAAAA3q1AAAAAAACAT0AAAAAAAIBLQAAAAAAAAEtAAAAAAAAAOUAAAAAAADB3QAAAAAAA2IxAAAAAAAAojUAAAAAAAFyaQAAAAAAA0HNAAAAAAABAeEAAAAAAAIBlQAAAAAAAAFVAAAAAAAAQdUAAAAAAAGyRQAAAAAAAWJxAAAAAAABUnkAAAAAAAA6hQAAAAAAACKFAAAAAAAC8l0AAAAAAAEycQAAAAAAAoJtAAAAAAAAAm0AAAAAAADiVQAAAAAAAqIVAAAAAAADwckAAAAAAAOySQAAAAAAACJFAAAAAAADgfkAAAAAAAKBwQAAAAAAAAF1AAAAAAACAc0AAAAAAAGiQQAAAAAAAHJxAAAAAAACgoEAAAAAAAHylQAAAAAAAoKZAAAAAAAD8okAAAAAAAF6kQAAAAAAAeqFAAAAAAACQnEAAAAAAAEyTQAAAAAAAkIJAAAAAAADgekAAAAAAAJB/QAAAAAAAQIxAAAAAAACYhkAAAAAAADB4QAAAAAAAIGRAAAAAAADgckAAAAAAAECPQAAAAAAAlKNAAAAAAAC0qUAAAAAAAN6sQAAAAAAABqtAAAAAAADUqUAAAAAAAGalQAAAAAAA5J9AAAAAAADklEAAAAAAAEBtQAAAAAAACIJAAAAAAADIgkAAAAAAAACBQAAAAAAAeIBAAAAAAAD4gUAAAAAAAEBpQAAAAAAAAPh/AAAAAABojkAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”metal”:[“nonmetal”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metalloid”,”nonmetal”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metal”,”metalloid”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metalloid”,”metalloid”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metalloid”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metal”,”halogen”,”noble gas”],”name”:[“Hydrogen”,”Helium”,”Lithium”,”Beryllium”,”Boron”,”Carbon”,”Nitrogen”,”Oxygen”,”Fluorine”,”Neon”,”Sodium”,”Magnesium”,”Aluminum”,”Silicon”,”Phosphorus”,”Sulfur”,”Chlorine”,”Argon”,”Potassium”,”Calcium”,”Scandium”,”Titanium”,”Vanadium”,”Chromium”,”Manganese”,”Iron”,”Cobalt”,”Nickel”,”Copper”,”Zinc”,”Gallium”,”Germanium”,”Arsenic”,”Selenium”,”Bromine”,”Krypton”,”Rubidium”,”Strontium”,”Yttrium”,”Zirconium”,”Niobium”,”Molybdenum”,”Technetium”,”Ruthenium”,”Rhodium”,”Palladium”,”Silver”,”Cadmium”,”Indium”,”Tin”,”Antimony”,”Tellurium”,”Iodine”,”Xenon”,”Cesium”,”Barium”,”Hafnium”,”Tantalum”,”Tungsten”,”Rhenium”,”Osmium”,”Iridium”,”Platinum”,”Gold”,”Mercury”,”Thallium”,”Lead”,”Bismuth”,”Polonium”,”Astatine”,”Radon”,”Francium”,”Radium”,”Rutherfordium”,”Dubnium”,”Seaborgium”,”Bohrium”,”Hassium”,”Meitnerium”,”Darmstadtium”,”Roentgenium”,”Copernicium”,”Nihomium”,”Flerovium”,”Moscovium”,”Livermorium”,”Tennessine”,”Oganesson”],”period”:[“I”,”I”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”],”standard state”:[“gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”symbol”:[“H”,”He”,”Li”,”Be”,”B”,”C”,”N”,”O”,”F”,”Ne”,”Na”,”Mg”,”Al”,”Si”,”P”,”S”,”Cl”,”Ar”,”K”,”Ca”,”Sc”,”Ti”,”V”,”Cr”,”Mn”,”Fe”,”Co”,”Ni”,”Cu”,”Zn”,”Ga”,”Ge”,”As”,”Se”,”Br”,”Kr”,”Rb”,”Sr”,”Y”,”Zr”,”Nb”,”Mo”,”Tc”,”Ru”,”Rh”,”Pd”,”Ag”,”Cd”,”In”,”Sn”,”Sb”,”Te”,”I”,”Xe”,”Cs”,”Ba”,”Hf”,”Ta”,”W”,”Re”,”Os”,”Ir”,”Pt”,”Au”,”Hg”,”Tl”,”Pb”,”Bi”,”Po”,”At”,”Rn”,”Fr”,”Ra”,”Rf”,”Db”,”Sg”,”Bh”,”Hs”,”Mt”,”Ds”,”Rg”,”Cn”,”Nh”,”Fl”,”Mc”,”Lv”,”Ts”,”Og”],”van der Waals radius”:{“__ndarray__”:”AAAAAAAAXkAAAAAAAIBhQAAAAAAAwGZAAAAAAAAA+H8AAAAAAAD4fwAAAAAAQGVAAAAAAABgY0AAAAAAAABjQAAAAAAAYGJAAAAAAABAY0AAAAAAAGBsQAAAAAAAoGVAAAAAAAAA+H8AAAAAAEBqQAAAAAAAgGZAAAAAAACAZkAAAAAAAOBlQAAAAAAAgGdAAAAAAAAwcUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBhQAAAAAAAYGFAAAAAAABgZ0AAAAAAAAD4fwAAAAAAIGdAAAAAAADAZ0AAAAAAACBnQAAAAAAAQGlAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBlQAAAAAAAwGNAAAAAAAAgaEAAAAAAACBrQAAAAAAAAPh/AAAAAADAaUAAAAAAAMBoQAAAAAAAAGtAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAA4GVAAAAAAADAZEAAAAAAAGBjQAAAAAAAgGhAAAAAAABAaUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”year discovered”:[“1766″,”1868″,”1817″,”1798″,”1807″,”Ancient”,”1772″,”1774″,”1670″,”1898″,”1807″,”1808″,”Ancient”,”1854″,”1669″,”Ancient”,”1774″,”1894″,”1807″,”Ancient”,”1876″,”1791″,”1803″,”Ancient”,”1774″,”Ancient”,”Ancient”,”1751″,”Ancient”,”1746″,”1875″,”1886″,”Ancient”,”1817″,”1826″,”1898″,”1861″,”1790″,”1794″,”1789″,”1801″,”1778″,”1937″,”1827″,”1803″,”1803″,”Ancient”,”1817″,”1863″,”Ancient”,”Ancient”,”1782″,”1811″,”1898″,”1860″,”1808″,”1923″,”1802″,”1783″,”1925″,”1803″,”1803″,”Ancient”,”Ancient”,”Ancient”,”1861″,”Ancient”,”Ancient”,”1898″,”1940″,”1900″,”1939″,”1898″,”1969″,”1967″,”1974″,”1976″,”1984″,”1982″,”1994″,”1994″,”1996″,”2003″,”1998″,”2003″,”2000″,”2010″,”2002″]},”selected”:{“id”:”1078″,”type”:”Selection”},”selection_policy”:{“id”:”1077″,”type”:”UnionRenderers”}},”id”:”1051″,”type”:”ColumnDataSource”},{“attributes”:{},”id”:”1079″,”type”:”UnionRenderers”},{“attributes”:{“data_source”:{“id”:”1030″,”type”:”ColumnDataSource”},”glyph”:{“id”:”1032″,”type”:”Text”},”hover_glyph”:null,”muted_glyph”:null,”nonselection_glyph”:{“id”:”1033″,”type”:”Text”},”selection_glyph”:null,”view”:{“id”:”1035″,”type”:”CDSView”}},”id”:”1034″,”type”:”GlyphRenderer”},{“attributes”:{“range”:{“id”:”1004″,”type”:”FactorRange”},”value”:-0.2},”id”:”1050″,”type”:”Dodge”},{“attributes”:{},”id”:”1080″,”type”:”Selection”},{“attributes”:{“callback”:null,”data”:{“CPK”:[“#FFFFFF”,”#D9FFFF”,”#CC80FF”,”#C2FF00″,”#FFB5B5″,”#909090″,”#3050F8″,”#FF0D0D”,”#90E050″,”#B3E3F5″,”#AB5CF2″,”#8AFF00″,”#BFA6A6″,”#F0C8A0″,”#FF8000″,”#FFFF30″,”#1FF01F”,”#80D1E3″,”#8F40D4″,”#3DFF00″,”#E6E6E6″,”#BFC2C7″,”#A6A6AB”,”#8A99C7″,”#9C7AC7″,”#E06633″,”#F090A0″,”#50D050″,”#C88033″,”#7D80B0″,”#C28F8F”,”#668F8F”,”#BD80E3″,”#FFA100″,”#A62929″,”#5CB8D1″,”#702EB0″,”#00FF00″,”#94FFFF”,”#94E0E0″,”#73C2C9″,”#54B5B5″,”#3B9E9E”,”#248F8F”,”#0A7D8C”,”#006985″,”#C0C0C0″,”#FFD98F”,”#A67573″,”#668080″,”#9E63B5″,”#D47A00″,”#940094″,”#429EB0″,”#57178F”,”#00C900″,”#4DC2FF”,”#4DA6FF”,”#2194D6″,”#267DAB”,”#266696″,”#175487″,”#D0D0E0″,”#FFD123″,”#B8B8D0″,”#A6544D”,”#575961″,”#9E4FB5″,”#AB5C00″,”#754F45″,”#428296″,”#420066″,”#007D00″,”#CC0059″,”#D1004F”,”#D90045″,”#E00038″,”#E6002E”,”#EB0026″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″,”#FF1493″],”EA”:{“__ndarray__”:”AAAAAABAUsAAAAAAAAAAAAAAAAAAAE7AAAAAAAAAAAAAAAAAAAA7wAAAAAAAQGPAAAAAAAAAHMAAAAAAAKBhwAAAAAAAgHTAAAAAAAAAAAAAAAAAAIBKwAAAAAAAAAAAAAAAAACARcAAAAAAAMBgwAAAAAAAAFLAAAAAAAAAacAAAAAAANB1wAAAAAAAAAAAAAAAAAAASMAAAAAAAAAAwAAAAAAAADLAAAAAAAAAIMAAAAAAAIBJwAAAAAAAAFDAAAAAAAAAAAAAAAAAAAAwwAAAAAAAAFDAAAAAAAAAXMAAAAAAAIBdwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBdwAAAAAAAgFPAAAAAAABgaMAAAAAAAFB0wAAAAAAAAAAAAAAAAACAR8AAAAAAAAAUwAAAAAAAAD7AAAAAAACARMAAAAAAAIBVwAAAAAAAAFLAAAAAAACASsAAAAAAAEBZwAAAAAAAgFvAAAAAAAAAS8AAAAAAAIBfwAAAAAAAAAAAAAAAAAAAPcAAAAAAAMBawAAAAAAAwFnAAAAAAADAZ8AAAAAAAHBywAAAAAAAAAAAAAAAAAAAR8AAAAAAAAAswAAAAAAAAAAAAAAAAAAAP8AAAAAAAMBTwAAAAAAAAC7AAAAAAACAWsAAAAAAAOBiwAAAAAAAoGnAAAAAAADga8AAAAAAAAAAAAAAAAAAADPAAAAAAACAQcAAAAAAAMBWwAAAAAAA4GbAAAAAAADgcMAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”IE-1″:{“__ndarray__”:”AAAAAACAlEAAAAAAAIiiQAAAAAAAQIBAAAAAAAAgjEAAAAAAAAiJQAAAAAAA/JBAAAAAAADolUAAAAAAAIiUQAAAAAAARJpAAAAAAABCoEAAAAAAAAB/QAAAAAAAEIdAAAAAAAAQgkAAAAAAAJiIQAAAAAAAoI9AAAAAAABAj0AAAAAAAIyTQAAAAAAAxJdAAAAAAAAwekAAAAAAAHCCQAAAAAAAyINAAAAAAACYhEAAAAAAAFiEQAAAAAAAaIRAAAAAAABohkAAAAAAANiHQAAAAAAAwIdAAAAAAAAIh0AAAAAAAFCHQAAAAAAAUIxAAAAAAAAYgkAAAAAAANCHQAAAAAAAmI1AAAAAAABojUAAAAAAANCRQAAAAAAAHJVAAAAAAAAweUAAAAAAADCBQAAAAAAAwIJAAAAAAAAAhEAAAAAAAGCEQAAAAAAAYIVAAAAAAADwhUAAAAAAADCGQAAAAAAAgIZAAAAAAAAgiUAAAAAAANiGQAAAAAAAIItAAAAAAABwgUAAAAAAACiGQAAAAAAAEIpAAAAAAAAoi0AAAAAAAICPQAAAAAAASJJAAAAAAACAd0AAAAAAAHB/QAAAAAAAmIRAAAAAAADIh0AAAAAAABCIQAAAAAAAwIdAAAAAAABAikAAAAAAAICLQAAAAAAAMItAAAAAAADQi0AAAAAAAHiPQAAAAAAAaIJAAAAAAABghkAAAAAAAPiFQAAAAAAAYIlAAAAAAADAjEAAAAAAADSQQAAAAAAAwHdAAAAAAADQf0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”atomic mass”:[“1.00794″,”4.002602″,”6.941″,”9.012182″,”10.811″,”12.0107″,”14.0067″,”15.9994″,”18.9984032″,”20.1797″,”22.98976928″,”24.3050″,”26.9815386″,”28.0855″,”30.973762″,”32.065″,”35.453″,”39.948″,”39.0983″,”40.078″,”44.955912″,”47.867″,”50.9415″,”51.9961″,”54.938045″,”55.845″,”58.933195″,”58.6934″,”63.546″,”65.38″,”69.723″,”72.64″,”74.92160″,”78.96″,”79.904″,”83.798″,”85.4678″,”87.62″,”88.90585″,”91.224″,”92.90638″,”95.96″,”[98]”,”101.07″,”102.90550″,”106.42″,”107.8682″,”112.411″,”114.818″,”118.710″,”121.760″,”127.60″,”126.90447″,”131.293″,”132.9054519″,”137.327″,”178.49″,”180.94788″,”183.84″,”186.207″,”190.23″,”192.217″,”195.084″,”196.966569″,”200.59″,”204.3833″,”207.2″,”208.98040″,”[209]”,”[210]”,”[222]”,”[223]”,”[226]”,”[267]”,”[268]”,”[271]”,”[272]”,”[270]”,”[276]”,”[281]”,”[280]”,”[285]”,”[284]”,”[289]”,”[288]”,”[293]”,”[294]”,”[294]”],”atomic number”:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118],”atomic radius”:{“__ndarray__”:”AAAAAACAQkAAAAAAAABAQAAAAAAAwGBAAAAAAACAVkAAAAAAAIBUQAAAAAAAQFNAAAAAAADAUkAAAAAAAEBSQAAAAAAAwFFAAAAAAABAUUAAAAAAAEBjQAAAAAAAQGBAAAAAAACAXUAAAAAAAMBbQAAAAAAAgFpAAAAAAACAWUAAAAAAAMBYQAAAAAAAQFhAAAAAAACAaEAAAAAAAMBlQAAAAAAAAGJAAAAAAAAAYUAAAAAAAEBfQAAAAAAAwF9AAAAAAABgYUAAAAAAAEBfQAAAAAAAgF9AAAAAAABAXkAAAAAAAEBhQAAAAAAAYGBAAAAAAACAX0AAAAAAAIBeQAAAAAAAwF1AAAAAAAAAXUAAAAAAAIBcQAAAAAAAgFtAAAAAAABgakAAAAAAAABoQAAAAAAAQGRAAAAAAACAYkAAAAAAACBhQAAAAAAAIGJAAAAAAACAY0AAAAAAAIBfQAAAAAAA4GBAAAAAAABgYEAAAAAAACBjQAAAAAAAgGJAAAAAAAAAYkAAAAAAAKBhQAAAAAAAQGFAAAAAAADgYEAAAAAAAKBgQAAAAAAAQGBAAAAAAAAgbEAAAAAAAMBoQAAAAAAAwGJAAAAAAABAYUAAAAAAAEBiQAAAAAAA4GNAAAAAAAAAYEAAAAAAACBhQAAAAAAAAGBAAAAAAAAAYkAAAAAAAKBiQAAAAAAAgGJAAAAAAABgYkAAAAAAAEBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAACBiQAAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”boiling point”:{“__ndarray__”:”AAAAAAAANEAAAAAAAAAQQAAAAAAAPJlAAAAAAABupUAAAAAAALGwQAAAAAAAzLBAAAAAAABAU0AAAAAAAIBWQAAAAAAAQFVAAAAAAAAAO0AAAAAAABCSQAAAAAAATJVAAAAAAADQpUAAAAAAAMqoQAAAAAAAUIFAAAAAAABwhkAAAAAAAOBtQAAAAAAAwFVAAAAAAAAgkEAAAAAAAHSbQAAAAAAAPqhAAAAAAADQq0AAAAAAAMCsQAAAAAAAAKdAAAAAAAA8okAAAAAAAHyoQAAAAAAAAKlAAAAAAADkqEAAAAAAAACpQAAAAAAAcJJAAAAAAABao0AAAAAAACqoQAAAAAAAuItAAAAAAADwjUAAAAAAAMB0QAAAAAAAAF5AAAAAAAAIjkAAAAAAANyZQAAAAAAARKxAAAAAAABKskAAAAAAAJmzQAAAAAAAMLNAAAAAAAC6sUAAAAAAAEexQAAAAAAAAK9AAAAAAABIqUAAAAAAAAajQAAAAAAAQJBAAAAAAABSokAAAAAAAHamQAAAAAAAEJ1AAAAAAAC0k0AAAAAAAJB8QAAAAAAAoGRAAAAAAACAjUAAAAAAAL6gQAAAAAAADLNAAAAAAABjtkAAAAAAAMS2QAAAAAAA7bZAAAAAAACltEAAAAAAAF2yQAAAAAAAArBAAAAAAAByqEAAAAAAALCDQAAAAAAASJtAAAAAAACYn0AAAAAAALScQAAAAAAATJNAAAAAAAAA+H8AAAAAAGBqQAAAAAAAAPh/AAAAAABon0AAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”bonding type”:[“diatomic”,”atomic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”diatomic”,”diatomic”,”atomic”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”covalent network”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”metallic”,”covalent network”,”atomic”,”metallic”,”metallic”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”ca”:[0,0,118,318,0,0,0,0,106,0,0,0,0,0,0,0,0,0,0,0,52,121,81,0,38,0,212,0,0,0,452,23,0,0,0,0,0,0,52,27,59,0,0,153,153,153,0,0,28,113,34,68,0,0,0,41,27,59,0,101,153,153,153,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],”density”:{“__ndarray__”:”4yZZPRaRFz8AAAAAAAAAAEjhehSuR+E/mpmZmZmZ/T+uR+F6FK4DQBSuR+F6FAJAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAK16NwPQrvP9ejcD0K1/s/mpmZmZmZBUCkcD0K16MCQB+F61G4Hv0/XI/C9Shc/z8AAAAAAAAAAAAAAAAAAAAAhetRuB6F6z/NzMzMzMz4P+xRuB6F6wdACtejcD0KEkBxPQrXo3AYQI/C9ShcjxxA4XoUrkfhHUB7FK5H4XofQM3MzMzMzCFAUrgehevRIUDXo3A9CtchQI/C9ShcjxxAmpmZmZmZF0BI4XoUrkcVQOxRuB6F6xZASOF6FK5HE0D2KFyPwvUIQAAAAAAAAAAAexSuR+F6+D8K16NwPQoFQOF6FK5H4RFACtejcD0KGkCkcD0K1yMhQI/C9ShcjyRAAAAAAAAAJ0A9CtejcL0oQGZmZmZm5ihACtejcD0KKEB7FK5H4fokQM3MzMzMTCFAPQrXo3A9HUA9CtejcD0dQM3MzMzMzBpA9ihcj8L1GEDD9Shcj8ITQHsUrkfheoQ/FK5H4XoU/j8UrkfhehQMQB+F61G4nipAZmZmZmamMEAAAAAAAEAzQIXrUbgeBTVA16NwPQqXNkCPwvUoXI82QNejcD0KFzVAzczMzMxMM0CPwvUoXA8rQDMzMzMzsydArkfhehSuJkCPwvUoXI8jQGZmZmZmZiJAAAAAAAAA+H97FK5H4XqEPwAAAAAAAPh/AAAAAAAAFEAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronegativity”:{“__ndarray__”:”mpmZmZmZAUAAAAAAAAD4f1yPwvUoXO8/H4XrUbge+T9SuB6F61EAQGZmZmZmZgRAUrgehetRCECF61G4HoULQNejcD0K1w9AAAAAAAAA+H/D9Shcj8LtP/YoXI/C9fQ/w/UoXI/C+T9mZmZmZmb+P4XrUbgehQFApHA9CtejBEBI4XoUrkcJQAAAAAAAAPh/PQrXo3A96j8AAAAAAADwP8P1KFyPwvU/pHA9Ctej+D8UrkfhehT6P4/C9Shcj/o/zczMzMzM+D9I4XoUrkf9PxSuR+F6FP4/j8L1KFyP/j9mZmZmZmb+P2ZmZmZmZvo/9ihcj8L1/D8UrkfhehQAQHE9CtejcAFAZmZmZmZmBECuR+F6FK4HQAAAAAAAAPh/PQrXo3A96j9mZmZmZmbuP4XrUbgehfM/SOF6FK5H9T+amZmZmZn5P0jhehSuRwFAZmZmZmZm/j+amZmZmZkBQD0K16NwPQJAmpmZmZmZAUDhehSuR+H+PwrXo3A9Cvs/exSuR+F6/D9cj8L1KFz/P2ZmZmZmZgBAzczMzMzMAEBI4XoUrkcFQAAAAAAAAPh/SOF6FK5H6T97FK5H4XrsP83MzMzMzPQ/AAAAAAAA+D/hehSuR+ECQGZmZmZmZv4/mpmZmZmZAUCamZmZmZkBQD0K16NwPQJAUrgehetRBEAAAAAAAAAAQFK4HoXrUQBApHA9CtejAkApXI/C9SgAQAAAAAAAAABAmpmZmZmZAUAAAAAAAAD4f2ZmZmZmZuY/zczMzMzM7D8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”electronic configuration”:[“1s1″,”1s2″,”[He] 2s1″,”[He] 2s2″,”[He] 2s2 2p1″,”[He] 2s2 2p2″,”[He] 2s2 2p3″,”[He] 2s2 2p4″,”[He] 2s2 2p5″,”[He] 2s2 2p6″,”[Ne] 3s1″,”[Ne] 3s2″,”[Ne] 3s2 3p1″,”[Ne] 3s2 3p2″,”[Ne] 3s2 3p3″,”[Ne] 3s2 3p4″,”[Ne] 3s2 3p5″,”[Ne] 3s2 3p6″,”[Ar] 4s1″,”[Ar] 4s2″,”[Ar] 3d1 4s2″,”[Ar] 3d2 4s2″,”[Ar] 3d3 4s2″,”[Ar] 3d5 4s1″,”[Ar] 3d5 4s2″,”[Ar] 3d6 4s2″,”[Ar] 3d7 4s2″,”[Ar] 3d8 4s2″,”[Ar] 3d10 4s1″,”[Ar] 3d10 4s2″,”[Ar] 3d10 4s2 4p1″,”[Ar] 3d10 4s2 4p2″,”[Ar] 3d10 4s2 4p3″,”[Ar] 3d10 4s2 4p4″,”[Ar] 3d10 4s2 4p5″,”[Ar] 3d10 4s2 4p6″,”[Kr] 5s1″,”[Kr] 5s2″,”[Kr] 4d1 5s2″,”[Kr] 4d2 5s2″,”[Kr] 4d4 5s1″,”[Kr] 4d5 5s1″,”[Kr] 4d5 5s2″,”[Kr] 4d7 5s1″,”[Kr] 4d8 5s1″,”[Kr] 4d10″,”[Kr] 4d10 5s1″,”[Kr] 4d10 5s2″,”[Kr] 4d10 5s2 5p1″,”[Kr] 4d10 5s2 5p2″,”[Kr] 4d10 5s2 5p3″,”[Kr] 4d10 5s2 5p4″,”[Kr] 4d10 5s2 5p5″,”[Kr] 4d10 5s2 5p6″,”[Xe] 6s1″,”[Xe] 6s2″,”[Xe] 4f14 5d2 6s2″,”[Xe] 4f14 5d3 6s2″,”[Xe] 4f14 5d4 6s2″,”[Xe] 4f14 5d5 6s2″,”[Xe] 4f14 5d6 6s2″,”[Xe] 4f14 5d7 6s2″,”[Xe] 4f14 5d9 6s1″,”[Xe] 4f14 5d10 6s1″,”[Xe] 4f14 5d10 6s2″,”[Xe] 4f14 5d10 6s2 6p1″,”[Xe] 4f14 5d10 6s2 6p2″,”[Xe] 4f14 5d10 6s2 6p3″,”[Xe] 4f14 5d10 6s2 6p4″,”[Xe] 4f14 5d10 6s2 6p5″,”[Xe] 4f14 5d10 6s2 6p6″,”[Rn] 7s1″,”[Rn] 7s2″,”[Rn] 5f14 6d2 7s2″,”[Rn].5f14.6d3.7s2″,”[Rn].5f14.6d4.7s2″,”[Rn].5f14.6d5.7s2″,”[Rn].5f14.6d6.7s2″,”[Rn].5f14.6d7.7s2″,”[Rn].5f14.6d9.7s1″,”[Rn].5f14.6d10.7s1″,”[Rn].5f14.6d10.7s2″,”[Rn].5f14.6d10.7s2.7p1″,”[Rn].5f14.6d10.7s2.7p2″,”[Rn].5f14.6d10.7s2.7p3″,”[Rn].5f14.6d10.7s2.7p4″,”[Rn].5f14.6d10.7s2.7p5″,”[Rn].5f14.6d10.7s2.7p6″],”group”:[“1″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″,”1″,”2″,”4″,”5″,”6″,”7″,”8″,”9″,”10″,”11″,”12″,”13″,”14″,”15″,”16″,”17″,”18″],”index”:[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117],”ion radius”:[“NaN”,”NaN”,”76 (+1)”,”45 (+2)”,”27 (+3)”,”16 (+4)”,”146 (-3)”,”140 (-2)”,”133 (-1)”,”NaN”,”102 (+1)”,”72 (+2)”,”53.5 (+3)”,”40 (+4)”,”44 (+3)”,”184 (-2)”,”181 (-1)”,”NaN”,”138 (+1)”,”100 (+2)”,”74.5 (+3)”,”86 (+2)”,”79 (+2)”,”80 (+2*)”,”67 (+2)”,”78 (+2*)”,”74.5 (+2*)”,”69 (+2)”,”77 (+1)”,”74 (+2)”,”62 (+3)”,”73 (+2)”,”58 (+3)”,”198 (-2)”,”196 (-1)”,”NaN”,”152 (+1)”,”118 (+2)”,”90 (+3)”,”72 (+4)”,”72 (+3)”,”69 (+3)”,”64.5 (+4)”,”68 (+3)”,”66.5 (+3)”,”59 (+1)”,”115 (+1)”,”95 (+2)”,”80 (+3)”,”112 (+2)”,”76 (+3)”,”221 (-2)”,”220 (-1)”,”48 (+8)”,”167 (+1)”,”135 (+2)”,”71 (+4)”,”72 (+3)”,”66 (+4)”,”63 (+4)”,”63 (+4)”,”68 (+3)”,”86 (+2)”,”137 (+1)”,”119 (+1)”,”150 (+1)”,”119 (+2)”,”103 (+3)”,”94 (+4)”,”62 (+7)”,”NaN”,”180 (+1)”,”148 (+2)”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”melting point”:{“__ndarray__”:”AAAAAAAALEAAAAAAAAD4fwAAAAAAYHxAAAAAAABgmEAAAAAAAFiiQAAAAAAA3q1AAAAAAACAT0AAAAAAAIBLQAAAAAAAAEtAAAAAAAAAOUAAAAAAADB3QAAAAAAA2IxAAAAAAAAojUAAAAAAAFyaQAAAAAAA0HNAAAAAAABAeEAAAAAAAIBlQAAAAAAAAFVAAAAAAAAQdUAAAAAAAGyRQAAAAAAAWJxAAAAAAABUnkAAAAAAAA6hQAAAAAAACKFAAAAAAAC8l0AAAAAAAEycQAAAAAAAoJtAAAAAAAAAm0AAAAAAADiVQAAAAAAAqIVAAAAAAADwckAAAAAAAOySQAAAAAAACJFAAAAAAADgfkAAAAAAAKBwQAAAAAAAAF1AAAAAAACAc0AAAAAAAGiQQAAAAAAAHJxAAAAAAACgoEAAAAAAAHylQAAAAAAAoKZAAAAAAAD8okAAAAAAAF6kQAAAAAAAeqFAAAAAAACQnEAAAAAAAEyTQAAAAAAAkIJAAAAAAADgekAAAAAAAJB/QAAAAAAAQIxAAAAAAACYhkAAAAAAADB4QAAAAAAAIGRAAAAAAADgckAAAAAAAECPQAAAAAAAlKNAAAAAAAC0qUAAAAAAAN6sQAAAAAAABqtAAAAAAADUqUAAAAAAAGalQAAAAAAA5J9AAAAAAADklEAAAAAAAEBtQAAAAAAACIJAAAAAAADIgkAAAAAAAACBQAAAAAAAeIBAAAAAAAD4gUAAAAAAAEBpQAAAAAAAAPh/AAAAAABojkAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”metal”:[“nonmetal”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metalloid”,”nonmetal”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”metal”,”metalloid”,”nonmetal”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metalloid”,”metalloid”,”nonmetal”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metalloid”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metalloid”,”halogen”,”noble gas”,”alkali metal”,”alkaline earth metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”transition metal”,”metal”,”metal”,”metal”,”metal”,”halogen”,”noble gas”],”name”:[“Hydrogen”,”Helium”,”Lithium”,”Beryllium”,”Boron”,”Carbon”,”Nitrogen”,”Oxygen”,”Fluorine”,”Neon”,”Sodium”,”Magnesium”,”Aluminum”,”Silicon”,”Phosphorus”,”Sulfur”,”Chlorine”,”Argon”,”Potassium”,”Calcium”,”Scandium”,”Titanium”,”Vanadium”,”Chromium”,”Manganese”,”Iron”,”Cobalt”,”Nickel”,”Copper”,”Zinc”,”Gallium”,”Germanium”,”Arsenic”,”Selenium”,”Bromine”,”Krypton”,”Rubidium”,”Strontium”,”Yttrium”,”Zirconium”,”Niobium”,”Molybdenum”,”Technetium”,”Ruthenium”,”Rhodium”,”Palladium”,”Silver”,”Cadmium”,”Indium”,”Tin”,”Antimony”,”Tellurium”,”Iodine”,”Xenon”,”Cesium”,”Barium”,”Hafnium”,”Tantalum”,”Tungsten”,”Rhenium”,”Osmium”,”Iridium”,”Platinum”,”Gold”,”Mercury”,”Thallium”,”Lead”,”Bismuth”,”Polonium”,”Astatine”,”Radon”,”Francium”,”Radium”,”Rutherfordium”,”Dubnium”,”Seaborgium”,”Bohrium”,”Hassium”,”Meitnerium”,”Darmstadtium”,”Roentgenium”,”Copernicium”,”Nihomium”,”Flerovium”,”Moscovium”,”Livermorium”,”Tennessine”,”Oganesson”],”period”:[“I”,”I”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”II”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”III”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”IV”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”V”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VI”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”,”VII”],”standard state”:[“gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”solid”,”liquid”,”solid”,”solid”,”solid”,”solid”,”solid”,”gas”,”solid”,”solid”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”,”NaN”],”symbol”:[“H”,”He”,”Li”,”Be”,”B”,”C”,”N”,”O”,”F”,”Ne”,”Na”,”Mg”,”Al”,”Si”,”P”,”S”,”Cl”,”Ar”,”K”,”Ca”,”Sc”,”Ti”,”V”,”Cr”,”Mn”,”Fe”,”Co”,”Ni”,”Cu”,”Zn”,”Ga”,”Ge”,”As”,”Se”,”Br”,”Kr”,”Rb”,”Sr”,”Y”,”Zr”,”Nb”,”Mo”,”Tc”,”Ru”,”Rh”,”Pd”,”Ag”,”Cd”,”In”,”Sn”,”Sb”,”Te”,”I”,”Xe”,”Cs”,”Ba”,”Hf”,”Ta”,”W”,”Re”,”Os”,”Ir”,”Pt”,”Au”,”Hg”,”Tl”,”Pb”,”Bi”,”Po”,”At”,”Rn”,”Fr”,”Ra”,”Rf”,”Db”,”Sg”,”Bh”,”Hs”,”Mt”,”Ds”,”Rg”,”Cn”,”Nh”,”Fl”,”Mc”,”Lv”,”Ts”,”Og”],”van der Waals radius”:{“__ndarray__”:”AAAAAAAAXkAAAAAAAIBhQAAAAAAAwGZAAAAAAAAA+H8AAAAAAAD4fwAAAAAAQGVAAAAAAABgY0AAAAAAAABjQAAAAAAAYGJAAAAAAABAY0AAAAAAAGBsQAAAAAAAoGVAAAAAAAAA+H8AAAAAAEBqQAAAAAAAgGZAAAAAAACAZkAAAAAAAOBlQAAAAAAAgGdAAAAAAAAwcUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBhQAAAAAAAYGFAAAAAAABgZ0AAAAAAAAD4fwAAAAAAIGdAAAAAAADAZ0AAAAAAACBnQAAAAAAAQGlAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAABgZEAAAAAAAIBlQAAAAAAAwGNAAAAAAAAgaEAAAAAAACBrQAAAAAAAAPh/AAAAAADAaUAAAAAAAMBoQAAAAAAAAGtAAAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAA4GVAAAAAAADAZEAAAAAAAGBjQAAAAAAAgGhAAAAAAABAaUAAAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8AAAAAAAD4fwAAAAAAAPh/AAAAAAAA+H8=”,”dtype”:”float64″,”shape”:[88]},”year discovered”:[“1766″,”1868″,”1817″,”1798″,”1807″,”Ancient”,”1772″,”1774″,”1670″,”1898″,”1807″,”1808″,”Ancient”,”1854″,”1669″,”Ancient”,”1774″,”1894″,”1807″,”Ancient”,”1876″,”1791″,”1803″,”Ancient”,”1774″,”Ancient”,”Ancient”,”1751″,”Ancient”,”1746″,”1875″,”1886″,”Ancient”,”1817″,”1826″,”1898″,”1861″,”1790″,”1794″,”1789″,”1801″,”1778″,”1937″,”1827″,”1803″,”1803″,”Ancient”,”1817″,”1863″,”Ancient”,”Ancient”,”1782″,”1811″,”1898″,”1860″,”1808″,”1923″,”1802″,”1783″,”1925″,”1803″,”1803″,”Ancient”,”Ancient”,”Ancient”,”1861″,”Ancient”,”Ancient”,”1898″,”1940″,”1900″,”1939″,”1898″,”1969″,”1967″,”1974″,”1976″,”1984″,”1982″,”1994″,”1994″,”1996″,”2003″,”1998″,”2003″,”2000″,”2010″,”2002″]},”selected”:{“id”:”1074″,”type”:”Selection”},”selection_policy”:{“id”:”1073″,”type”:”UnionRenderers”}},”id”:”1037″,”type”:”ColumnDataSource”},{“attributes”:{“text”:{“field”:”symbol”},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”text_font_style”:”bold”,”x”:{“field”:”group”,”transform”:{“id”:”1029″,”type”:”Dodge”}},”y”:{“field”:”period”}},”id”:”1032″,”type”:”Text”},{“attributes”:{“fill_alpha”:{“value”:0.6},”fill_color”:{“field”:”symbol”,”transform”:{“id”:”1022″,”type”:”CategoricalColorMapper”}},”height”:{“units”:”data”,”value”:0.95},”line_color”:{“field”:”symbol”,”transform”:{“id”:”1022″,”type”:”CategoricalColorMapper”}},”width”:{“units”:”data”,”value”:0.95},”x”:{“field”:”group”},”y”:{“field”:”period”}},”id”:”1025″,”type”:”Rect”},{“attributes”:{“text”:{“field”:”symbol”},”text_alpha”:{“value”:0.1},”text_baseline”:”middle”,”text_color”:{“value”:”black”},”text_font_style”:”bold”,”x”:{“field”:”group”,”transform”:{“id”:”1029″,”type”:”Dodge”}},”y”:{“field”:”period”}},”id”:”1033″,”type”:”Text”}],”root_ids”:[“1001″]},”title”:”Bokeh Application”,”version”:”1.4.0″}}
(function() {
var fn = function() {
Bokeh.safely(function() {
(function(root) {
function embed_document(root) {
var docs_json = document.getElementById(‘1279’).textContent;
var render_items = [{“docid”:”883d95fd-ecd4-4d16-ab52-790f2f46dd06″,”roots”:{“1001″:”6e232c55-8e62-4f75-aae4-61b1ebf4c511”}}];
root.Bokeh.embed.embed_items(docs_json, render_items);
}
if (root.Bokeh !== undefined) {
embed_document(root);
} else {
var attempts = 0;
var timer = setInterval(function(root) {
if (root.Bokeh !== undefined) {
clearInterval(timer);
embed_document(root);
} else {
attempts++;
if (attempts > 100) {
clearInterval(timer);
console.log(“Bokeh: ERROR: Unable to run BokehJS code because BokehJS library is missing”);
}
}
}, 10, root)
}
})(window);
});
};
if (document.readyState != “loading”) fn();
else document.addEventListener(“DOMContentLoaded”, fn);
})();
Because these minerals tend to concentrate in specific countries like niobium in Brazil or antimony in China and remain central to many areas of society such as national defense or engineering, governments like the US have come forward with listing these minerals as “critical.”
The abundance across different continents is shown in the map above.
You can find gallium, the most abundant of the critical minerals, in place of aluminum and zinc, elements smaller than gallium. Processing bauxite ore or sphalerite ore (from the sediment-hosted, Mississippi Valley-type and volcanogenic massive sulfide) of zinc yield gallium. The US meets its gallium needs through primary, recycled and refined forms of the element.
German and indium have uses in electronics, flat-panel display screens, light-emitting diodes (LEDs) and solar power arrays. China, Belgium, Canada, Japan and South Korea are the main producers of indium while germanium production can be more complicated. In many cases, countries import primary germanium from other ones, such as Canada importing from the US or Finland from the Democratic Republic of the Congo, to recover them.
Rechargable battery cathodes and jet aircraft turbine engines make use of cobalt. While the element is the central atom in vitamin B12, excess and overexposure can cause lung and heart dysfunction and dermatitis.
As one of only three countries that processes beryllium into products, the US doesn’t put much time or money into exploring for new deposits within its own borders because a single producer dominates the domestic berllyium market. Beryllium finds uses in magnetic resonance imaging (MRI) and medical lasers.