It’s easy to think of cognition and emotion as separate from one another, but research in cognitive science and neuroscience have suggested the two are more closely linked than we’d like to believe. Cognition can be defined as activities related to thought processes that let us gain knowledge about the world while emotions would be what we feel that involve physiological arousal, evaluation of what we experience, how our behavior expresses them, and the conscious experience of emotions themselves. To understand how cognition and emotion interact with one another in the brain, we may view cognitive behaviors neuroscientific phenomena as the result of both cognition and emotion, rather than simply one or the other. With research spanning philosophy, cognitive science, and neuroscience, emotions are no longer considered antagonistic to reason the way ancient Greek and Roman scholars treated them. Now, philosophers are much more inclined to view them closely linked through ideas such as reason being a slave to passion or reason giving way to passion through subjective experience.
Evidence of the mere-exposure effect, that people prefer things merely because they’re more familiar with them, in 1980 by psychologists William Raft Kunst-Wilson and R. B. Zajonc and as well as other findings in behavioral research shifted debates to focus on affect as a feature primary to yet independent of cognition. It could be related to unconscious processing and subcortical activity with cognition related to conscious processing and cortical involvement.
Researchers generally agree on what constitutes cognition. Cognition, including memory, attention, language, problem-solving, and planning, often involve controlled neurological processes that respond to stimuli in the environment. This may include maintaining information while an external stimulus attempts to distract the mind. When cells in the dorsolateral prefrontal cortex of a monkey maintains information in the mind for brief periods of time, we can describe this link as a neural correlate for the cognitive process. With functional MRI (fMRI), we can identify which part of the brain are involved in these cognitive processes. Emotion, on the other hand, is much more subject to debate among scientists and philosophers.
Emotions are arguably the most important part of our mental life to maintain quality and meaning of existence. We find meaning in emotions and rely on them to make sense of the world, sometimes in ways cognitive processes don’t offer. When researching emotion, some incorporate drive, motivation, and intention behind them as part of these states of mind.
Other researchers may use emotions in the conscious or unconscious assessment of events such as a feeling of disgust in the mouth. Subcortical parts of the brain such as the amygdala, ventral striatum, and hypothalamus are often linked to emotions. These brain structures are conserved through evolution and operate in a fast, sometimes automatic way. Still, how the different parts of the complex circuitry of the brain can mediate specific emotions is under research and debate. Neuropsychologists, neurologists and psychiatrists are only recently understanding the role of emotional processing in more complicated brain functions like decision-making and social behavior.
But there’s much more to emotions than the physical phenomena in the brain.
Imagine coming across a terrifying bear while hiking. In our most immediate reaction of fear, we can evaluate the situation (the bear is dangerous), a bodily change (increase heart rate), a phenomenological perception (feeling unpleasant), an expression of fear (eyelids raised and mouth open), a behavior component (wanting to run away), and a mental evaluation (focused attention on our surroundings). The phenomenological part involves our subjective experience as we respond to the world around us. All of these features come together in our emotions and can be debated to different degrees of necessity and sufficiency to emotions. On top of that, emotions may be directed towards objects with our intention (such as feeling angry at someone rather than just feeling anger on its own) and can shave motivation with respect to behavior (such as acting out of anger). Researchers have also debated whether emotions describe ourselves or emotions express ourselves imperatively. They’ve debated how the brain implements different types of emotions and how neural mechanisms describe emotional phenomena.
Cognitive theories of emotions that have become popular in the latter half of the 20th century can be differentiated between constitutive and causal theories. Constitutive theories use emotions as cognitions or evaluations, while for causal theories, emotions are caused by cognitions or evaluations. For example, being frightened by a grizzly bear involves a judgement that the bear is scary. The fear may be the judgement itself or the result of the judgement. They let us differentiate between the complicated interactions of cognition emotion such as determining whether someone’s anger in response to a situation is the result of a cognitive evaluation of the situation or a reaction that’s more natural and automatic. In the mid-twentieth century, philosophers C. D. Broad and Errol Bedford emphasized constitutive approaches to emotion which would become dominant in philosopher while causal ones more popular in psychology. These philosophers argued that, if emotions had intentionality, there would be internal standards of appropriateness to which an emotion is appropriate. These cognitive evaluations, identifying emotions with judgements, have been used by philosophers such as Robert Solomn, Jerome Neu, and Martha Nussbaum since then. Identifying emotions with judgements, judgementalism, have been pivotal in cognitive theories of emotions.
Judgementalism in this way, however, doesn’t explain how emotions motivate, the subjective phenomenal experience of emotions, how one can experience an emotion with being able to identify a judgement with it, or a “recalcitrance to reason,” how we experience emotions even when they go against judgements that contradict them. Judgementalists may counter these issues by determining what judgements emotions are such as “enclosing a core desire,” as Solomon has argued, to let them motivate or “dynamic”, as Nussbaum has argued, so they may account for these issues. Through these methods, they may involve accepting how the world seems even with contradictory judgements.
Other work in the 1960s showed how the cognitive component of emotions directly interacted with the physical bodily changes that occur alongside them. Psychologists Stanley Schachter and Jerome Singer developed a theory of emotion, known as the two-factor theory or Schachter-Singer theory, in which emotion is how we cognitively evaluate our bodily response to emotions. Injecting participants with epinephrine to arouse their subjects, the participants were told the drug would improve their eyesight with some of them additionally being told about the side effects. When witnessing other people act either happily or angrily, the participants who didn’t know about the side effects were more likely to feel either happier or angrier than the ones who were. The two theorized that, if people experienced an emotion without an explanation, they’d label their feelings using the feelings in the moment, suggesting participants without an explanation were susceptible to the emotional influences of others. The theory has faced criticism that it confuses emotions with how we label them such that we need complete knowledge of our emotions to label them as well as difficulty in explaining how we may experience emotions even before we think of them. Research in neuroscience has shown thinking about stimuli in ways to increase the emotion may boost prefrontal or amygdala activity while decreasing the emotion may reduce it.
Integrating data and research from various parts of the brain, as they can provide the basis for cognitive phenomena, would illustrate a greater picture of emotion and cognition. There are many structures involved in functions and many functions for the individual structures of the brain. These neuron computations that underlie those phenomena also have affective and cognitive components, as described by cognitive scientists and philosophers. Viewing the relationship between emotion and cognition as a tug-of-war between the two doesn’t accurately capture the relationship between emotions and how we thinking about them. A combination of research in neuroscience, cognitive science, and philosophy would do justice.
Now I ain’t sayin’ she’s a Heidegger, but she ain’t messin’ with no alt-right thinkers.
They say time flies. With age, the days feel shorter. Life speeds up, and it doesn’t slow down. The years start coming, and they don’t stop coming. However we look at it, we can understand how our perception has sped up in making these observations. It may be the result of memory. Every moment that passes and feels faster in our lives lets us view the present and the near-present with greater and and greater detail while losing the memories of what has gone long ago. We watch time speed up as we remember less.
Writing and other forms of immortalizing our words can fight against this. Whether its art, music, poetry or any other way of recording the tangible and conceivable into permanence, we can escape the fleeting visions of this world. As though we were waking up from a dream and recounting what had just happened, we can recognize dream states are part of our reality as Heidegger’s “Being-there” of the Dasein would describe.
The Dasein is what makes our existence more than a point in space-time that brings being from nothing. With death distinguishing existence, Dasein is the “being-toward-death” that gives our lives temporality. When Heidegger examined classical metaphysics with the hopes of creating a new ontological philosophy, he differentiated between the being and reality. All things have being while reality does not exist. Reality does not have the awareness of the world around it, and existing is what lets us determine what lies beyond ourselves. He described the technological advances of the 1930s and 1940s as threatening the world of ideas – poetry, intellectual thought, forms of art, and whatever we need to preserve who we are. Humanity becomes an object with an instrumetnal purpose through information and communication. Appreciating art and posing questions of who we are counteract these forces.
Much the same way Dennett wrote about his own dreams taking a long time, yet, in retrospect, seemed to have not taken any time at all, we may hypothesize that there is no dream experience. Instead, when we awaken, our memory banks play the dreams to us. Heidegger might respond to this claim by arguing that the times of dreams are consistent with the experience of dreams themselves.
With time moving faster, the present and the near-present become punctuated by events with less and less time between them. We find disparate events – whether its a meme about raiding Area 51 or the dispersion of fake news – coming and moving closer to one another. Our near-present perception enters a hypersensitive state that responds to the chaos and frenzy, and we can pick our poison: international turmoil, threats to the planet’s climate, the rise of fringe political groups, or whatever keeps us from falling asleep, as though we were trying to wake up from a nightmare. Even something as benign as a mock competitions between YouTube channels can turn messy when a shooter tells his audience to “subscribe to PewDiePie” before massacring a mosque.
It’s possible, though, that things had always been like this. The rise of Nazism during Heidegger’s time would lead historians to associate the philosopher and his views with the fascist movement. Heidegger watched rationalism, scientism, and market-centric forces overtake wonder, liberation, and freedom. Machines themselves reduced humans to the darkness they had created, and the fascists began attacking the mind-body dualism of Jews and liberals. The alt-right echoes Heidegger’s yearning for certainty and fixed values in modern life as well as nationalism and the interconnectedness of humans and the land. Trump’s former chief strategist Steve Bannon held up a biography of Heidegger and said “That’s my guy,” when he was interviewed by Der Spiegel.
Heidegger soon denounced Nazism. After he saw Hitler’s worship of efficiency and mythologized machines as though they were part of nature itself – part of who we are and how things should be – he condemned the anti-intellectualism running rampant. The racism and anti-Semitism followed an “I do not think, therefore I am,” inversion of Descartes’s famous proclamation.
When Horace wrote Caelum non animum mutant qui trans mare currunt (“those who rush across the sea change the sky above them, not their soul”), our souls still desire a connection to something permanent and fixed. Even Aristotle’s observation that we can only benefit from studying ethics when we already have “noble habits,” the philosopher must already have an idea of what she wants to learn. Heidegger believed that the philosopher with a main idea that she is a rooted being, tied to time and place and living within and through a land and language, her only interest is that she was born, worked, and died.
If only modern political discourse could heed the guidance of Aristotle. The philosopher’s first treatise on politics described a middle class that would lead to liberalist ideals by later intellectuals like Locke. The free rule because of their virtue and responsibility to rule. The commitment to philosophical thought, at the very least, eases the burden of time.
Nature embraces with all her ill,
The creatures being by her will,
Seduced by the scorpion’s cunning skill,
The frog and him were killed.
The scorpion’s sting was in his nature,
The ultimate cause of the dictator.
How humans fight like gladiators
For fear of our behavior.
The scorpion stung, the frog was fraught,
A lesson of nature’s punishment brought.
Yet men, endowed with rational thought,
Can act as they ought.
But reason with instinct become a hindrance,
The guilt and shame for our existence,
As we may keep these sins at distance.
Then man and nature, different.
The real part (red) and imaginary part (blue) of the Riemann zeta function along the critical line Re(s) = 1/2. The first non-trivial zeros can be seen at Im(s) = ±14.135, ±21.022 and ±25.011. The Riemann hypothesis, a famous conjecture, says that all non-trivial zeros of the zeta function lie along the critical line.
For some, mathematics much more than a matter of solving problems. It transcends abstraction and intellectual pursuit into a way of determining meaning from life. For a brother and sister, it can mean a relentless search for truth that reads like a Romantic fable. A history that consists of settings across time and space punctuated by individual actions and events, the novelist creates a narrative that sheds light on a new meaning of truth. Truth may be elusive, especially in a post-truth society, but, in a metamodernist manner, it’s closer to reality – an authentic, original reality – than it seems.
In Karen Olsson’s The Weil Conjectures: On Math and the Pursuit of the Unknown, she intertwines the stories of French brother and sister André and Simone Weil during a Europe in the midst of World War II. The former, a mathematician known for his contributions to number theory and algebraic geometry, and the latter, a philosopher and Christian mystic whose writing would go on to influence intellectuals like T.S. Eliot, Albert Camus, Irish Murdoch, and Susan Sontag. Hearkening back to the childhood of the siblings, we follow their stories studying poetry, mathematics, tragedies, and other artists and scientists. Between these glimpses of their lives, Olsson throws in her personal anecdotes studying mathematics as an undergraduate at Harvard. She describes a “euphoria” from thinking hard about mathematics such that, while knowledge itself is the goal, it’s a disappointment to reach it. You lose your pleasure and sensation in seeking truth once you find it. André characterizes his own search for happiness through this search for truth. Drawing parallels between herself and the siblings, their stories depend less on the context that surrounds them and more on the similarities in their narratives.
With multiple stories happening at once, the reader feels a sense of timelessness in the writing. The plot has less to do with one event happening after another, but more with a grand narrative carrying each part of the story with one another. A mix of elements of modernism and postmodernism together, Olsson’s book serves as a sign of the next step: metamodernism. In separate directions, mathematics and philosophy, the two venture for truth that seems to lie just outside their reach. Olsson tells the narratives through letters between the siblings, the notebooks upon which Simone scribbled her thoughts – philosophic, mathematical, and religious. On the purposes of mathematics and philosophy, Olsson questions how mathematics had become disconnected from the world around them. So focused on attacking problems in an abstract, self-referential setting, the field’s myopic focus on truth had strayed from meaning, she believed. Simone’s story through working in factories and a Resistance network with a wish to free herself from the biases of her own self would lead to her death by starvation in solidarity towards war victims.
If the labor of machinery is so oppressive, Simone wondered how to create a successful revolution technological, economic, and political. The pain she sought through suffering made her who she was. It humanized her as she wrote about the German army defeating France. The evil in the world was God revealing, not creating, the misery inside us. Simone sought to achieve a state of mind that liberated herself from the material pursuits of the world through philosophy and Christian theology. She wanted an asceticism to provide she could a morally principled life on her self-imposed rules. This included donating money during her career as a teacher so that she would earn the same amount as the lowest-paid teachers.
D. McClay, senior editor of The Hedgehog Review, wrote that Simone’s own struggle with Catholicism partly had to do with her anti-Semitism in his essay “Tell Me I’m OK.” “Though Weil was herself Jewish, she did not identify as Jewish in any significant sense, and her sense of solidarity with the oppressed did not extend to other Jews,” McClay said. Feminist philosopher Simone de Beauvoir who, according to her memoir, didn’t get along with Weil when they met, offers a contrast to Weil in how to live a good life.
In Beauvoir’s The Ethics of Ambiguity, she argued existentialist ethics are rooted in recognition of freedom and contingency, McClay said. Beauvoir wrote, “Any man who has known real loves, real revolts, real desires, and real will knows quite well that he has no need of any outside guarantee to be sure of his goals; their certitude comes from his own drive…. If it came to be that each man did what he must, existence would be saved in each one without there being any need of dreaming of a paradise where all would be reconciled in death.” Beauvoir’s atheism created friction with Weil, McClay said. They also define a reality of what we do in the world that defines their own “drive,” which seems like a response to the threats of existential nothingness.
McClay continued to compare the two Simones to provide an account for how to live a moral life, involving abandoning the idea of a “good person” in favor of goodness without regard to how others judge us. “It might mean living more like Weil—taking what you need, and giving away the surplus—”, McClay said, “with the caveat that one takes what one actually needs.” Beauvoir and Weil, moral philosophers that describe how “we are always, simultaneously, together and alone,” may even be guides for the crises of our age. Living together and alone, through the community of one another and the isolation of intellectual work, we can live like Weil intended. McClay’s writing also shows this mix of modernity’s unified, centralized identity withothers with postmodernism’s decentered self.
Interspersed in Olsson’s book are stories about Archimedes’ having “eureka” moments, René Descartes’ search for the “unknown” (x in algebra), L. E. J. Brouwer’s work in topology, and even the mathematician Sophie Germain who studied mathematics in secrecy and corresponded with male mathematicians under a pseudonym. Tracing the foundations of mathematics, language, and other tenets of society to the Babylonians, she carefully compares the methods of problem solving and invention using language to reveal deeper nature of the phenomena (“Negative numbers infiltrated Europe during the Middle Ages” making mathematics seem deceptive or insidious) or method in discovery (“Are numbers real or not? Were they discovered or invented? We pursue this question for a couple of minutes.”). The figures comment on their own judgements on the deeper meaning and purpose in their work such as George Cantor saying “I see it, but I do not believe it.” Olsson drops these quotes and glimpses of history in between moments of trials of other characters.
When the early 20th-century Jewish-born mathematician Felix Hausdorff set the grounds for modern topology, an anti-semitic mob claiming they would send him to Madgascar where he could”teach mathematics to the apes” gathered around his house. Olsson then switches to her perception that she always read André and Simone Weil’s last name as “wail,” despite it actually pronounced as “vay.” Then, Olsson returns to Hausdorff’s story of taking a lethal dose of poison after failing to find a way to escape to America. In a farewell letter to his friend Hans Wollstein, who would later die in Auschwitz, Hausdorff wrote “Forgive us our desertion! We wish to you and all our friends to experience better times.” Olsson’s juxtaposition of the “wail” last name alongside the Kristallnacht, a systematic attack on Jews, compares the personal struggles of André and Simone as inseparable from the Nazi’s persecution of Jews – as though the siblings were “wailing” in response to their persecution. It also emphasizes Olsson’s own perception of the siblings that, no matter how hard she tries, she still has her own take on the story. Even when she shares the rise of Nazis in Europe, Olsson’s limited perspective preserves the postmodern disunity of culture alongside a modern master narrative. The art of narration is both a process of Olsson’s own struggles to share and an authenticated, objective authority of knowledge that can forgive Hausdorff’s suicide and provide a better future for everyone.
With Descartes’ discovery of the “unknown,” he also introduced methods of standard notation of mathematics that would let researchers use superscripts (x² as “x squared”) and subscripts (x₀as “x naught”). Olsson demonstrates the similarities between the methods of reasoning that let mathematical invention become the same engine underneath the creation of science, art, and literature, as French mathematician Jacques Hadamard explained. Hadamard’s interest of what goes on in a mathematician’s mind as they do what they do was also in response to the crisis of modernity having witnessed the horrors of both world wars. The mathematician frequently seek new ways of looking at problems in mathematics as researchers came and visited during seminars twice a week. The pieces of each story come together in a flow that uses a variation in style, length, and meaning to create a multidimensional work of art that is the book. Each passage flows seamlessly in the interplay between exposition and narrative, description and action, showing and telling.
At one point, Simone and André’s reading habits are interrupted by the narrator of Clarice Lispector’s Agua Viva proclaiming mathematics as the “madness of reason.” The rational, coherent, commonsense nature of mathematics would seem to contradict the foolish wildness of madness. But, as an interruption to Simone’s love of Kant and Chardin as a child and André’s interest in the Bhagavad Gita in college, this “madness of reason” becomes more apparent. In Why This World: A Biography of Clarice Lispector, Benjamin Moser wrote:
My passion for the essence of numbers, wherein I foretell the core of their own rigid and fatal destiny,” was, like her meditations on the neutral pronoun “it,” a desire for the pure truth, neutral, unclassifiable and beyond language, that was the ultimate mystical reality. In her late works, bare numbers themselves are conflated with God, now without the mathematics that binds them, one to another, to lend them a syntactical meaning. On their own, numbers like the paintings she created at the end of her life, were pure abstractions, and as such connected to the random mystery of life itself. In her late abstract masterpiece Água Viva she rejects “the meaning that her father’s mathematics provide and elects instead the sheer “it” of the unadorned number: “I still have the power of reason-I studied mathematics which is the madness of reason-but now I want the plasma-I want to feed directly from the placenta.
The Renaissance depiction of madness as an intrinsic part of man’s nature is found in the literature and philosophy of the time period. An imbalance, or excess, of reason could lead to the madness that seeks this mysterious, “pure truth” that transcends language itself. Much the same way Simone and André seek the essence through different forms of this “madness.” Simone’s personal battles with health and existential issues seem more alike a mathematician’s search for reason. Olsson later mentions the “madness of reason” as she narrates her own lonely experience “trying to demonstrate small truths” an undergraduate in her lonely dorm room on a cold, wintery day. It’s a localized truth that Olsson finds in her work, but still remains part of a grander narrative that connects their stories. The interjecting quote from Lispector’s text highlights this search for truth in the stories of Simone, André, and Olsson herself.
According to Olsson, Descartes used “x” to refer to the unknown because the printer was running out of letters, but there may have been an aesthetic choice in addition to the pragmatic use. “x “ would come to mean that which we don’t know in other contexts such as sex shops and invisible rays. Olsson continues her personal story asking the question “What is my unknown? My x?” She narrates her venture back to mathematics after writing novels in her time since she graduated from Harvard University.
Olsson emphasizes Simone’s inferiority complex to her brother as one of the primary causes for this perspective on the world. Simone’s own desire to be a boy, use the name “Simon,” and absence of any lover while André proposed the Weil Conjectures, married, and had children show these contexts. She found truth in this suffering and disregard for material pleasures – even chasing states of mind in which she could perceive the world in a state of purity and without any biases of her own self. The conjectures would become the foundation for modern algebra, geometry, and number theory.
When Olsson took a course under Harvard mathematician Barry Mazur, she didn’t dare speak to him. The conjecture, Mazur explained, would lay down the basis of a theory, expectations believed to be true, driven by analogy. Olsson still recalls her feeling of awe when she first learned and geometry and the power of understanding the world without memorizing it. After André was arrested while on vacation in Finland in 1939 on suspicion of spying, he barely missed execution when a Finnish mathematician suggested to the chief of police during a dinner before the day of the execution to deport him instead. While André is forced by train to Sweden and England, Olsson returns to her childhood excitement in middle school learning about “math involving letters.” She then recalls moments teaching her two-year-old daughter how to count as the child asks “Where are numbers?” When Olsson returns to André’s story, now as he’s transferred to a prison in France and requires unidle intellectual activity, she comments that escaping France was a more pressing problem than anything in mathematics.
As André longs for an ability to engage in research even in the cloistered sepulchre of a prison cell, he writes to Simone comparisons of mathematics to art. Simone is allowed to visit him for a few days a week, and the two rassure each other that they’re okay. André tells Simone he told an editor to send page proofs of his article to her so she can copyedit them. The writing between the two goes into stories of Babylonians and Pythagoreans reminiscent of the dialogue the two siblings had as children. Olsson’s own story intertwined with the communication between Simone and André serves as a parallel to demonstrate that she, too, can make mathematics accessible to the common person the same way Simome did with André’s work. André’s colleagues would even start to envy the quiet solitude of prison in which he could produce work undisturbed. Comparing mathematics to art, though, André described the material essence of a sculpture that limit a mathematician’s objectivity while remaining an explanation in and of itself. In this sense, it has both objective and subjective value the same way a mix of modern and postmodern story would. Simone doubted this, though. Works of art that relied on a physical material didn’t directly translate to a material for the art of mathematics. Though the Greeks spoke of the material of geometry as space, André’s work, Simone argued, was an inaccessible system of previous mathematical work, not a connection between man and the universe.
The brother responded with the role of analogy in mathematics far beyond a mental activity. It was something you felt, a version of eros, “a glimpse that sparks desire,” Olsson wrote. Going through the history of mathematics from the nineteenth-century watershed time in which questions of numbers were solved using equations, the mathematician feels “a shiver of intuition” in connecting different theories. Simone would imagine societies built upon mathematics, mysticism, and existential loneliness. Through this, all of Olsson’s jumping between stories becomes clear. She had set the reader up to view mathematics as an art the way André did and, through the world Simone created, something the general audience could understand. Olsson continues with her personal experience as an undergraduate being recommended by a professor to write about mathematics for a general audience as a career alongside dream sequences of André and Simone.
In 1938, Simone attended a Bourbaki conference, a group of French mathematicians that André had initiated with the purpose of reformulating mathematics on an abstract and formal, yet self-contained basis. The mathematicians would sign their names collectively as “Bourbaki” on papers as they attempted to unify contemporary mathematics with a common language just as Euclid did centuries ago. While the group members would yell at one another with hard-hitting questions, even threatening at times, Simone began to believe that mathematics should be made more accessible to a mass audience. The Bourbaki group’s vision lead them to describe hundreds of pages of set theory before defining the number 1. They sought to create an idea of mathematics as a system of maps and relationships that were more important than the intrinsic qualities of numbers and other mathematical objects themselves. Scientific American would call André “the last universal mathematician.” This method of universalizing while still emphasizing relationships among objects shows a modernist tendency, the former, interacting with a postmodernist one, the latter.
Olsson’s own stories through studying mathematics as a student and teaching her children She explains the highlight of her mathematics career was finding the answer to a course problem before one of her classmates did. Her humility and sense of humor make her writing all the more approachable and relatable.
The book’s weakness is that the individual stories feel abbreviated at times. Olsson switches back and forth between many narratives that may leave the reader feeling confused or even frustrated that desires and beliefs of the characters are unexpanded. It can make it difficult to get committed to the story events or feel connected to characters when their moments are so brief and spread out across the book. The short snippets of stories across time and space alongside Olsson’s juxtaposition of them with one another make the reading easy to understand for anyone without a strong background in either mathematics or philosophy. Still, much the same way Olsson describes the search for truth, it leaves the reader in a perpetual search. We get a feeling of excitement that we are bound to get to the correct answer to a problem or find meaning in research while still never quite achieving it.
Olsson’s book serves as a beacon of the power of evidence and justification in a post-truth world. Olsson addresses the constant searches for truth and meaning in our current society by capturing opposites and extremes in her writing. The empirical, hypothesis-driven mathematics and speculative, argument-driven philosophy contrast one another on the meandering search for truth. The isolation of intelligence for both André and Simone in their work contrast the warmth of community and social engagement the two find in their respective environments. Truth becomes less of something that we must obtain by being on one side or the other and more of finding appropriate methods of addressing problems. It’s objective in that it lies in the techniques of various disciplines, but constructed because it comes from the individual’s choice. In a typical mix of modernism and postmodernism, Olsson’s personal story to find the answers to her personal curiosities by turning back to mathematics demonstrates this mix of the personal with the impersonal.
Like postmodern stories, Olson’s book is non-linear and reveals truth as a series of localized, fragmented pieces. Like modernism, we find greater purposes and narratives between the different stories as a testament to the power of science and technology. It switches between the progressive, exalted story of André with the melancholic, tragedy of Simone with parallels between the stories together. The grand themes of the power and style of mathematics and philosophy dictate the rules and principles that set the foundation for the stories. André’s story and Simone’s may even be treated with the former as a modernist tale of the triumph of science and the latter, a postmodern warning of society’s so-called “progress.” In regular metamodernist fashion, Olsson uses elements of both modernism and postmodernism in her book. In metamodernist fashion, the two searches for truth become one and the same. Philosophy may ask “Why?” but, for mathematics, the question is “y₀?”
“You better be careful telling him something’s impossible. It better be limited by a law of physics or you’re going to end up looking stupid.” – Max Hodak, Neuralink president
As the gap between humans and computers becomes smaller every day, the startup Neuralink, backed by figures including Elon Musk, Vanessa Tolosa, and other individuals, recently hosted a public conference in which they revealed their efforts create neural interfaces between brains and computers. The futuristic dream of a brain-computer interface for mutual exchange of information between humans and works of artificial intelligence may sound like something out of a science fiction dream, but the neural interface, a device to enable communication between the human nervous systems and computers, would include invasive brain implants and noninvasive sensors on the body.
During the livestream on July 16, 2019, Neuralink revealed their work to the public for the first time with the pressing goal of treating neurophysiological disorders and a long-term vision of merging humans with artificial intelligence. With $158 million in funding and nearly 100 employees, the team has made advances in flexible electrodes that bundle into threads smaller in width than human hair inserted into the human brain. As the computer chip processes brain signals, the first product “N1” is meant to help quadriplegic individuals using brain implants, a bluetooth device, and a phone app.
In their paper “An Integrated Brain-Machine Interface Platform with thousands of channels,” Musk and other team members noted that electrode impedances after coating were really low allowing for efficient information transmission. Each electrode uses pixels at 3 Hz bandwidth to measure spikes, a neuron’s responding to stimuli that are generally about 200 Hz but can reach up to 10 kHz at times. The dense web that the team creates would let them feed the entirety of a brain’s activity to a deep learning program for creating artificial intelligence at a great degree of accuracy, study the neuroscientific basis for phenomena, or even decode the basics of other features such as language. For the Human Connectome project, an initiative to create a complete map of the human brain, Neuralink’s scale would give more precision than the project has done before.
This precision could address the ethical issues raised when the cognitive response of a brain-computer interface doesn’t appropriately match what a patient communicates. Neuralink’s work should take into account the risks associated with such a fine level of precision. Most strikingly, brain-computer interfaces so intimate to who we are raise the ethical issues of whether neurologically compromised patients can make informed decisions about their own care. Philosopher Walter Glannon said in his paper “Ethical issues with brain-computer interfaces,” the capacity to make decisions is a spectrum of cognitive and emotional abilities without a specific threshold that would indicate how much constitutes the ability to make an informed decision. Just as philosophers and ethicists have studied the basis for ethical frameworks in the decision-making process among physicians, patients, and other roles in health care, the complex semantic processing of brain-computer interfaces may not constitute enough to show a patient has the cognitive and emotional capacity to make an informed and autonomous decision about life-sustaining treatment. It would need some a behavioral interaction between the patient and the health care professional so that the brain-computer interface’s response reflects only what it’s capable of communicating.
Tim Urban of “Wait But Why” described Neuralink as Musk’s effort to reach the “Wizard Era” – in which everyone could have an AI extension of themselves – “A world where AI could be of the people, by the people, for the people.” The promise of cyborg superpowers as humans step into the digital world calls back to science fiction stories such as 2001: A Space Odyssey and Jason and the Argonauts. From the electrode array that joins the limbic system and cortex of the human brain gives Nerualink the information for those regions of the brain. It creates a reality in which information and the metaphysical nature of what we are depend less on the physical structures of the brain itself, but, rather the information of the human body. Prior to artificial intelligence, the brain evolved to develop communication, language, emotions, and consciousness through the slow, steady, aimless walk of natural selection, and a collective intelligence that can contribute to machine learning algorithms like Keras and IBM Watson. The Neuralink interface would let us communicate effortlessly with anyone else in the collective intelligence. The AI extension of who are means that the machines that are built upon this information are part of us as much as they are machines. With machines connecting all humans, we achieve a collective intelligence that goes against how human and animal minds have evolved over the past hundred million years.
How do you trust others? What makes you become suspicious when working with other people? Though we rely on collecting information about others when making decisions, the ways we collect that information may change how others perceive us. People may be less likely to trust others when they inquire about their behavior in a way that appears suspicious, a new study shows.
Decisions of whether to trust other people can vary based on risk and uncertainty. In simulating how people trust one another using a game between trustees and investors, researchers studied social context, monetary cost, and the trustee’s trustworthiness to show that an investor appearing suspicious may lessen trust and appearing averse to betrayal, increase trust.
Using computational models of how individuals collecting information before making an investment decision, the researchers examined the intuitive patterns behind why participants made the decisions they did. They tested participants under conditions of whether collecting information cost money and whether the trustee would know the investor was collecting information. Participants gathered less information when it came at a cost and when they could find conclusive results from the information about others.
The researchers tested various model to determine which one fit the experimental results best. When the difference between outcomes that would favor investing was different enough from those that wouldn’t, participants stopped collecting information. To test how strong of a role suspicion played in these decisions, they compared the Cost of Appearing Suspicious (CAS) model against a Sample Cost model, an Uncertainty model, and a discrete Drift Duffusion Model (dDDM). For the CAS, Sample Cost, and Uncertainty models, the participants’ decisions are Bayesian in the sense they determined how likely they are to invest based on their previous beliefs about either the trustee or the investor.
The CAS model used a suspicion factor, that gathering information decreases the probability of investment. The Sample Cost model does not use this suspicion factor, and, under the Uncertainty model, participants would stop when the posterior belief distribution width dropped below a tolerance threshold. Under the dDDM, on the other hand, participants would collect information until their evidence for trustworthiness or untrustworthiness met a certain criteria. After determining how well models fit various conditions on the individual level, they found the CAS model predicted better than the others, and it even fit well to investment decisions after collecting information.
When individuals choose to invest or not, scientists have proposed various models for decision-making across different contexts. They come into play as people choose whether to work with or trust others. One study in the Proceedings of the National Academy of Sciences showed, when people work together, they care about whether their partner gathers information about how much they would profit if they defected. They instead engage in blind cooperation cooperate among trustworthy and untrustworthy people, but don’t collect information to make themselves appear suspicious. This is further shown that people are perceived as selfish when they gather information for their own profit in a study in the Journal of Behavioral and Experimental Economics.
The work has practical applications in information collection and use for psychiatric disorders. Biases in collecting information when information is uncertain or scarce has been associated with weighing negative information heavily in depression and compulsivity. How well we model the moral character of other individuals are central to disorders like borderline personality disorder and autism.
The homunculus depicts how the body represents itself in the somatosensory cortex of the brain.
Physical tasks the may seem basic to humans can be much more complicated for machines. The sheer number of degrees of freedom and dimensions the brain must use to make something as versatile and complex as hand motions means that the brain must reduce these high-dimensional spaces to achieve these feats of motion. This is a method of taking complicated processes such as the movement of individual fingers and finding ways of classifying these movements so that they may be accessed without as much information as they would otherwise take. Computational neuroscientists Yuke Yan and James G. Goodman along with biologist Sliman J. Bensmania observed the musculoskeletal movements of human and monkey hand kinematics during sign language, typing, and grasping objects with a principal component analysis. This let them figure out how the motions were specific to certain conditions such as the object trapped or the letter signed using linear discriminate analysis to classify different conditions.
They removed components in descending order of variance by reconstructing the hand posture on each trial and classified them using linear discriminant analysis to determine how many experimental results could be classified correctly. This let them determine the functions of complicated hand gestures using a small number of variables that represent the various motions. Using combinations that account for the motions, this would let researchers understand how such intricate, complicated motions can be governed by a set of neurons or neurophysiological mechanisms. They tested how similar the results were between humans and monkeys and found monkeys had hand postures that weren’t as specific for different objects.
Finally the researchers classified hand motions using spike counts of neurons in the primary motor cortex to determine which ares of the brain corresponded with different motions. This gave them an overarching picture from neuroscience to behavior in how the brain makes sense of complicated, concerted movements.
Other methods of taking advantage of the probability let scientists create maps that can measure across variables in space. One may use a stochastic process, a family of random variables, on a space of probabilities to choose appropriate parts of the space that correspond with different outcomes. This can be applied from simple axon models of individual neurons to entire neural networks.
Very little is known about exactly how the brain interprets somatosensory activity as a particular tactile sensation. Some initial evidence towards understanding this comes from individuals with brain damage due to stroke. Researchers studying the somatosensory cortex of the brain, the part linked with tactile localization, have shown that hands and forearms tend to mislocalize sensations of touch towards their centers in healthy individuals and those who have had strokes in somatosensory regions. Psychologists Janellen Huttenlocher and Susan Duncan and statistician Larry Hedges proposed that spatial locations bias towrds the middle of categorical spaces and away from boundaries the more uncertain their information is. This method of dealing with uncertainty is another example of how the brain simplifies problems when it needs to.
Flies and humans use coding strategies when processing visual information to create more-refined images. Fly and cone photoreceptors respond to light by adapting their gain to a local mean intensity. This creates a contrast between intensity at the receptor and the local mean. The receptors then code the response to this contrast among all the values of input light. This way, the nervous system simplifies intensities to proportions that are more easily evaluated by the neuron’s response range. It also lets the fly or human identify same objects under different lighting.
Modern science can uncover ancient wisdom. While it may seem regressive or pseudoscientific to study concepts from Traditional Chinese Medicine (TCM), they reveal deeper meanings about who we are as humans when subject to scrutiny by the scientific method. The herb formulas, plant-derived nature produces of TCM are still used in disease prevention and treatment despite the dominance of modern science. When medical researchers performed machine learning classification methods on 646 herbs are according to organ systems, known as Meridians, they found the 20 molecule features were most important for predicting these Meridian. It included structure-based fingerprints and properties of absorption, distribution, metabolism, and excretion. As the first time molecular properties of herb compounds have been associated with Meridians, this provides molecular evidence of Meridian systems.
The Meridian system dictates how he life-energy qi flows through the body. Qi includes actuation of the body, warming, defense again excess, containment of body fluids, and transformation between qi and food, drink, and breath. Each Meridian corresponds to a yin yang quality, an extremity (hand or foot), one of the five elements (metal, fire, earth, wood, or water), an organ (such as heart or kidney), and a time of day. The yin yang qualities describe how complementary, opposite forces of the universe interact, such as Greater Yin or Lesser Yang. Given these roots in traditional, non-scientific thought, scholars have debated the scientific justification behind why and how TCM works. In their paper “Predicting Meridian in Chinese Traditional Medicine Using Machine Learning 2 Approaches,” the researchers assumed Meridian can be found through scientific methods to begin with. The five elements are qi are metaphysical, not modern physiological or medical phenomena. The researchers emphasized the need to examine the herb medicine actions as they relate to disease etiology to create a formal understanding of TCM.
Qi and yin yang as they relate to human health date back to texts of discussion and debates from the Warring States period (475–221 BC) of ancient China. Philosopher Zhaunghzi noted qi was the basis of the body’s physical being with the six qi (wind, cold, summer heat, fire, dryness, and damp) in harmony with one another as they affect the seasons. These theories would be used in medicine to describe relations and analogies between the body, the state, and the cosmos, or the universe.
Scientists and philosophers alike have examined and pondered about consciousness, one of the most central problems in our experience of the world. Both approaches may seek different methods, with science being empirical and philosophy, speculative, but they’re both relevant to any discussion on such a complicated phenomena. Understanding how neural correlates of conscious experience correspond to various parts in the brain lets scientists take “bottom-up” approaches of beginning with empirical phenomena and determining what cognitive and psychological behaviors result. On the other hand, beginning with the philosophy of mental states, including beliefs, intents, desires, emotions, knowledge, and figuring out how those can be attributed to the mind moves in the opposite direction. These mental states are whatever is the nature of the mental phenomena the mind occupies. It’s the way the brain makes sense of the world. A combination of empirical neural data from both computational and psychological models alongside a philosophical analysis would let us bridge the gap between the brain and consciousness. Either way, researchers end up with a neurobiologically accurate view of the brain in how consciousness emerges. There are many challenges to neuroscience explaining consciousness and its findings have philosophical significance to many ideas in epistemology, ethics, and metaphysics.
The difficulty of the subjective experience presents a challenge to consciousness. Any person’s experience is an external phenomena to anyone else. Philosopher Edmund Husserl’s notions of phenomenological and natural attitude show this relationship between the first- and third-person experiences. When someone perceives a car, their consciousness is directed at the car and that person is not necessarily aware of the details of the experience, such as what the steel car feels like. This is Husserl’s natural attitude. When that person focuses on the experience of perceiving the car as its own experience, it is a phenomenological attitude. A neuroscientist would generally concern themselves with the external phenomena they research and endorse the natural attitude. But the concepts of a scientific model (such as water being composed of two hydrogen atoms and one oxygen) are conscious phenomena a neuroscientist uses to understand the model. The neuroscientist can use the phenomenological attitude towards those models as experiences, and this shows we can’t escape our own point of view. Even a scientific model is a representation in one’s mind.
Consciousness as a neuroscientific phenomena requires a study of this relationship between an experience and the scientific model of it. The gap between the two can depend upon whether one endorses a realism view of science or an antirealism one. Under realism, mature scientific theories can be true and describe the world such that the gap is non-existent or narrow. Scientific realism means that all natural phenomena can be modeled using the structures and relations among them. We may model qualitative feelings, or qualia, our subjective experiences, using these structures and relations. It still leaves certain experiences difficult, such as how one may see the color red as a structural relationship given that introspection about redness doesn’t reveal its nature. Anti-realism, on the other hand, dictates we can only say whether a neuroscientific theory of consciousness is compatible with observations, not whether it captures nature. There is a large epistemic gap between any concrete phenomenon and the corresponding scientific models. The experiences are not different in this respect.
Before the 20th century difference between philosophy and science, philosophers generally studied consciousness through both philosophical and scientific means. French philosopher René Descartes performed research in mathematics, neuroscience, and philosophy. Psychologist-philosopher William James would create philosophical theories in light of empirical psychology research. With the rise of logical positivism, the idea that only statements that can be empirically verified are meaningful, in the early 20th century, philosophers focused on the semantic content of arguments instead of empirical scientific results. During this time, the three traditional perspectives of the mind-brain question, physicalism, mentalism, and dualism, emerged. Physicalism is the thesis that everything can be reduced to physical phenomena, mentalism, to mental phenomena, and dualism, that everything is either mental or physical. he rise of physicalism in the late 19th century meant to take consciousness as unscientific in some interpretations. Philosopher Galen Strawson’s realistic physicalism means the physical nature of the nervous system can manifest consciousness through mental activity. This can be illustrated with an example of philosopher Frank Jackson’s knowledge argument.
The argument uses the fictional story of a famous neuroscientist Mary who learns everything about the world through a computer but remains confined to a room that is entirely black and white. If physicalism were true, one might argue Mary knows everything about the world, but, because she has not experienced color, she does not know what it is. Upon seeing color, this argument would dictate that she would experience a subjective experience of her consciousness that she had never encountered before and, therefore, learns something new – showing she did not know everything about the world. One may conclude, from this line of reasoning, physicalism doesn’t entail everything. Possible responses to this may include the ability hypothesis – that Mary learns how to see color, but doesn’t learn what color is, therefore, what she learns doesn’t contradict that she knew everything about what the world was.
The historical trends meant changes, not only for consciousness, but for science as a whole. Scientific terms began taking new meanings. With the rise of thermodynamics around the turn of the 20th century, heat went from meaning boiling water to a specific dimension of temperature variation. Consciousness became an empirical phenomena of brain activity variation.
Consciousness presents researchers with the problem of how to explain when a mental state is conscious rather than not as well as what the content of a conscious state is given the subject experience of everyone’s consciousness. From a philosophical perspective, we rely instead on behavior and introspective testimony on the nature of consciousness in searching for common features from which we deduce knowledge about consciousness. From the neuroscientific angle, we study the central nervous system and the neural properties in the cerebral cortex. Psychologists Jussi Jylkka and Henry Railo have argued scientific models of consciousness need to explain consciousness’ constituents, contents, causes, and causal power. Though consciousness has many aspects to it, we focus on perception in this essay. Consciousness can further be differentiated into phenomenal consciousness, the properties of experience that correspond to what it’s like to have those experiences, and access consciousness, consciousness based on which states one can access.
The global neuronal workspace explains when a mental state is in consciousness such that it is accessible to systems related to memory, attention, and perception. Accessing content means it can use its content in performing computations and processing. Consciousness resides in these accessed states by the cortical structure of the brain that is involved with perceptual, mnemonic, attentional, evaluational and motoric systems. Whatever neurons are involved in someone’s current state constitute the workspace neurons. They activate such that the neural activation causes activity between workspace systems. It’s tempting to say the cortical workspace network correlates with the phenomenon of consciousness itself especially given imaging results can show which areas of the brain activate when a subject is conscious, but this correlation doesn’t tell us whether brain activity is of phenomenal or access consciousness.
Another approach, recurrent processing theory, ties perceptual to processing consciousness without a workspace and, instead, a focus on activity connecting sensory areas of the brain. It uses first-order neural representation, that we may perceptually represent the content of a mental state to mean perceiving that content, to explain consciousness. Interconnected sensory systems may use feedforward and feedback connections, such as those in the first cortical visual area, V1, which carry information to higher-level processing areas. The forward sweep of processing uses feedback connections linking visual areas. Global workspace theory and recurrent processing theory differ in the stages of visual processing they depend upon. The four stages of visual processing are superficial feedforward processing (process visual signals locally in the visual system), deep feedforward processing (the signals can influence action), superficial recurrent processing (information travels to previously visited visual areas), and widespread recurrent processing (across broad areas such as the global workspace access). Recurrent processing at the third stage, superficial recurrent processing, is necessary and sufficient for consciousness according to recurrent processing theory, and at the fourth stage, widespread recurrent processing, for the global workspace theory.
Philosopher Victor Lamme has argued that superficial recurrent processing is sufficient for consciousness because features of widespread recurrent processing are also found in superficial recurrent processing. Recurrent processing is found in both stages, and the global neuronal workspace theory allows superficial recurrent processing to correlate with widespread processing. Lamme believes that, in response to visual stimuli, there is first a fast forward sweep of processing, proceeding through the cortex. This first stage is nonconscious. Only a second stage of recurrent processing, when earlier parts of the visual cortex are activated once more by feedback from later parts, is taken to be conscious (with, again, empirical support).
Another approach to consciousness holds that one can be in a conscious state if and only if one represents oneself in that state. If one were in a conscious visual state of seeing am moving, that person must represent themselves in that visual state. The higher-order state represents the first-order state of the world and results from the consciousness of the first-order state. One must be aware of a conscious state to be in it. This lets neuroscientists correlate empirical work on higher-order representations of states with prefrontal cortex activity. For some higher-order theories, one can be in a conscious state by representing oneself even if there is no visual system activity.
Neuroscientists can use empirical tests of higher-order theory against other accounts, but neurologist Melanie Boly has argued that individuals with the prefrontal cortex removed can still have perceptual consciousness. This may prefrontal cortical activity isn’t necessary for consciousness, but one may argue the experiments didn’t remove all of the prefrontal cortex or that the prefrontal cortex is necessary, but in a more complicated system than previously suggested. Psychologist Hakwan Lau and philosopher Richard Brown have used experimental results to suggest consciousness cannot exist without the corresponding sensory processing as predicted by some higher-order accounts.
Finally, the Information Integration Theory of Consciousness (IIT) uses integrated information to explain whether one is in a state of consciousness. Integrated information is the effective information parts of a system carry in light of the causal profile of the system. If the information a system carries is greater than the sum of the information of each of the individual parts, then the information of that system is integrated information. IIT holds that this integrated information implies that a neural system is consciousness, and, the more integrated information there is, the more conscious the system is. Neuroscientist Giulio Tononi has argued the cerebellum has a low amount of consciousness compared to the cortex as it has far fewer connections even though it has more neurons. IIT suffers from treating many things as conscious even when they don’t seem to be. Tononi has proposed that a loop connecting the thalamus and cortex forms a dynamic core of functional neural clusters, varying over time. This core is assumed to integrate and differentiate information in such a way that consciousness results.
Neuroscientist J. H. van Hateren has presented a computational theory of consciousness in which the neurobiology of the brain allows it to compute a fitness estimate by a specific inversion mechanism that also causes the feeling of consciousness. His conjecture that consciousness is a transient and distinct cause the individual produces when he or she prepares to communicate—externally or internally. Citing the thalamocortical feedback loop, the internal variables involved in this process estimate the individual’s evolutionary fitness.
Despite how flashy it sounds to say researchers can completely understand consciousness, the challenges that neuroscientists and philosophers face mean things are far from completely figured out. There remains a lot to be discovered and examined from both scientific and philosophical angles.
With the ethical concerns raised by issues of gene editing of human embryos, academic ethics research has set the foundation for and discussed the bioethical threats mankind faces. Alongside artificial intelligence (AI) and similar issues such as data science privacy and the power of social media, the steps into baby manufacturing are illustrated through a mix of modernist and postmodernist ideologies and require a revised notion of a biological-digital autonomy that can account for the changing self. The CRISPR-Cas9 gene editing technology have already shocked and disgusted scholars in science and philosophy around the world. Questions of how much of who we are we should be able to change and what we should do with the rapid power of artificial intelligence on the horizon have taken center stage. With the newfound metamodernism appraoch to science, reality, and existence, we step into gene editing the same way we jump off the deep end of a lake and hold our breath until we rise to the surface.
The oft-repeated truism “science is moving so fast that ethics just can’t keep up” couldn’t be farther from the truth. Ignoring the baseless assumption that science and ethics were racing against one another, the scientistic idea that philosophers and ethicists in similar fields have not addressed the power and potential of science would be to disregard the decades of ethics research on genetic engineering. The claim also seems to treat science as an uncontrollable force that must be braced against because we can’t do anything to stop it. It’s false that mankind has complete control over nature, but the notion inaccurately portrays mankind as weak and vulnerable to the world when we can take a metamodernist approach that rests somewhere in between. Researchers in ethics have been paying close attention. They’ve been studying everything closely.
Society and individuals have been shifting from postmodernism into metamodernism. We create the self as something between a postmodernist and modernist notion of reality through gene editing. As opposed to postmodernist traditions that nothing is real and modernist ones that reality is there beyond media, language, and symbols, right now we’re sure reality is somewhere in the middle in our notions of metamodernism. We are both a modernist believer in the power of science and technology and a postmodernist skeptical of the reality we find. Genetic engineers have begun using pluirpotent stem cells, ones that have the same properties of embryonic stem cells but come from manipulating ordinary adult cells rather than destroying embryos, that are more effective in providing dozens or hundreds of offspring for individual parent cells. As more stem cell research goes into how male sex cells can result from female cells and vice versa, this could even allow single parents or same-sex couples to produce biological children. Researchers have even predicted scenarios in which children result from the DNA of more than two biological parents, known as “multiplex parenting.”
Recent success in both cloning and CRISPR technologies have let scientists understand better the embryology and developmental physiology of human embryos as a result of the pluripotent stem cell advancements and in vitro fertilization (IVF). We must warn of the issues that may arise as stem cell reproduction methods gear towards manufacturing embryos for desirable traits. Couples who choose to keep their unwanted embryos frozen or donate them to further research or to other couples need to be aware of how those embryos are being used to assess their role of responsibility in stem cell research.
This stem cell method comes with the advantage as the daughter cells result similar to the adult ones, and researchers have posed solutions for the issues of eugenic control that would result. We can critique these ideas for their shortcomings in characterizing the eugenics movement. These movements do not thoroughly emphasize the social forces governing how individuals would be manufactured. To address the issues raised by gene editing, we need a deeper, more multidimensional view of the moral problems raised by eugenic control that accounts for the changing self and reality in a metamodernist world. We can engage in these subjects through personal narratives and humanized ideas of who we are that embrace ethics and threats of existentialism.
Researchers have, however, brought up solutions that derive from dangerous principles of eugenics and extreme notions of individual autonomy. In the transition to metamodernism, they prevent mankind from pushing back against looming threat of a full-fledged surveillance state, and, instead disregard the idea that a particular line of research can be inherently morally wrong. These transhumanist thinkers such as philosopher Nick Bostrom (who has also warned about the threat of Superintelligence) who proposes a solution to use stem cell sex cells for performing eugenic selection for intelligence, partially as a method for combating superintelligent AI. If humans can replicate natural selection on a group of embryos over the course of several generations, they can produce the most intelligent humans possible. This eugenics approach isn’t uncommon, either. Ethics professor Nicholas Agar wants prospective parents to choose how they can improve their children in a “liberal eugenics” fashion. This sort of scientific perfection fails to capture how these humans would supposedly relate to the rest of society given that they’ve attacked the fundamental ideals of community and sharedness that humans share. Bostrom does suggest there may be religious or moral grounds to prohibit this method of creating genetically enhanced children, but claims having children at a disadvantage to those around them would cause everyone to eventually pick up the technique. This reasoning rests on a dangerous egalitarian notion of human success and morality driven by competition in a way that forces those who disagree to accept the technique. It doesn’t rest upon morally reasoned principles or the virtues of humanism and research. Much the same way individuals would rapidly evolve under Bostrom’s scheme, the entirety of society should follow suit regardless of choice.
Bostrom’s idea also doesn’t recognize the reality of how natural selection and evolution work. Much like natural selection, this method wouldn’t automatically and instantly choose the most optimal DNA. Instead, it would choose a heritable trait without regard to DNA the same way nature influences which traits are optimal for survival and reproduction. Bostrom’s method relies on knowing which parts of the DNA are responsible for the trait which can be edited directly without the need for cycling through generations. Besides, the genetic basis for these traits have been shown to be limited as the traits themselves are a complicated amalgamation of environmental interactions, genetic pathways, what epigenetic factors activate throughout an individuals’ lifetime, how nature would “select” for certain traits, and the resulting phenotypes. It wouldn’t dictate how a superintelligent human may emerge. The typical issues of the artificial selection process being prone to error and having an inherent natural selection to it raise concerns as well. All of this lies on the inhumane assumption that we may find human perfection through genes regardless of how an objectified individual may control their own fate and what right they have to do so. Indeed, the vacuous claim that “science is moving so fast that ethics just can’t keep up” only measures unethical, unjustified notions of how fast science is moving to begin with.
The ethics of some reproductive technologies become blurrier in light of the newly complex understanding of heredity’s cross-currents. A maternal surrogate, for example, will likely exchange stem cells with the fetus she carries, opening the door to claims that baby and surrogate are related. If the surrogate later carries her own baby, or that of a different woman, are the children related? Parenthood becomes even stranger with so-called mitochondrial-replacement therapy. If a woman with a mitochondrial disorder wants a biological child, it is now possible to inject the nucleus of one of her eggs into a healthy woman’s egg (after removing its nucleus), and then perform in vitro fertilization. The result is a “three-parent baby,” the first of which was born in 2016. Zimmer doesn’t presume to make ethical judgments about procedures such as this, but warns that “informed consent” in such cases can be unexpectedly difficult to determine.
The more honored individuals in bioethics such as Stanford law professor Henry Greely have voiced similar arguments. Greely has argued insurance companies and government agencies can help fund the effective DNA sequencing methods in fighting genetic disease. In his book The End of Sex and the Future of Human Reproduction, he predicts how we may perceive and judge the potential of stem cell technologies. He notes he wouldn’t ban embryos created from a single parent, but would still require pre-implamentation genetic diagnosis to select for optimal offspring. But, above all, Greely emphasizes that these should be closely scrutinized by a standing commission that can recognize what principles all people would believe in. What sort of principles all individuals would agree upon, such as the four common principles of medical ethics: autonomy, beneficence, non-maleficence, and justice, are up for debate. The principles of parenthood should be upheld even for extreme scenarios of the future that may select for the most desirable traits such that biological parenthood becomes meaningless. We must protect every notion of humanity that comes from our current methods of reproduction, both biologically and artificially, to address these issues.
With the growing threat of AI, namely that computers may become more and more human-like, our autonomy should reflect how the self has been changing through these innovations. The self can be changed artificially much the same way robots and computers are programmed, but they’re not completely fragmented that humans share nothing with one another. These stem cell methods can give humanity a more unified individualistic self that, when appropriately regulated, allow for even modified individuals to exercise appropriate rights and responsibilities. Greely’s ideas still disgust by suggesting market-driven factors to influence human reproductive choices. The principles that doctors and scientists must stand upon are far too likely to become cold, calculated treatments for dehumanized problems. Professor of public health Annelien L. Bredenoord and professor of bioethics Insoo Hyun argued in “Ethics of stem cell‐derived gametes made in a dish: fertility for everyone?” multiplex parenting will shake the very notions of responsibility and autonomy and moreso than other reproductive techniques. They will disgust individuals, citing ideas of the reaction by professor of philosophy Martha Nussbaum’s book Hiding from Humanity: Disgust, Shame, and the Law. Phyisican Leon Kass noted there is wisdom in this repugnance in his paper “The Wisdom of Repugnance: Why We Should Ban the Cloning of Humans.” No amount of sociological or psychological research into the well-being of multiplex children can prevent this natural sense of disgust that we feel at this idea – and with good reason. We must hold onto this disgust and other aesthetic, physiological responses and assess them to the extent which they provide us with moral clarity. From there, a metamodernistic view of gene editing can take place. Writer Carl Zimmer noted in She Has Her Mother’s Laugh that he doesn’t make ethical judgments about multiplex parenting, but “informed consent” in such cases can difficult to determine.
Reading, learning, and writing about these issues is the first step. For anyone to learn more about science and technology in this age would help spread humanism to fight ignorance. These issues need to enter the sphere of public debate and discussion in contrast to how they’re currently only governed by scientists, ethicists, and philosophers. We need laws in place to prevent these catastrophic consequences long before they occur. In our metamodernist society, we need not reject science and technology entirely. We may remain skeptical of the notions of progress and reality, but only to a point where we can begin a new direction for scientific research. Given the existential crises of genetic engineering and artificial intelligence, we may imagine a moral society through personal development and psychological growth in wrestling with and understanding these struggles. We need a humanized notion of reproduction to address psychological needs of individuals in a society that has the power of gene editing. We can create a grand narrative that mankind has an overarching worldview to connect all humans to one another, but hold it lightly enough to recognize the limits of what we know and should do. We can understand that we may create an idea of “reality” and methods of understanding the world around us that respect scientific research while still questioning the authority of problematic research techniques. By creating a “reality,” we can embrace the truths that we can create a moral society that determines who we are despite the changing self brought upon by genetic engineering and the digital age. We can determine what is honest, authentic, and true without being cynical, showing contempt for the beliefs and sensibilities of others, and turning to eugenics approaches for solutions. Metamodernism, as it begins to infect all areas of life, means our scientific research should seek elegant, morally refined methods that we embrace for knowledge.
Only then will we come closer to our selves in a metamodernist future. The intellectual thought to counter the doomsday dystopia scenarios of the future can involve selecting for desirable traits in offspring through trustworthy, verified methods that acknowledge the rights and responsibilities of the individual. We must remain skeptical of harmful progress, but remain open to gene editing technologies insofar as they may help mankind without raising ethical concerns.

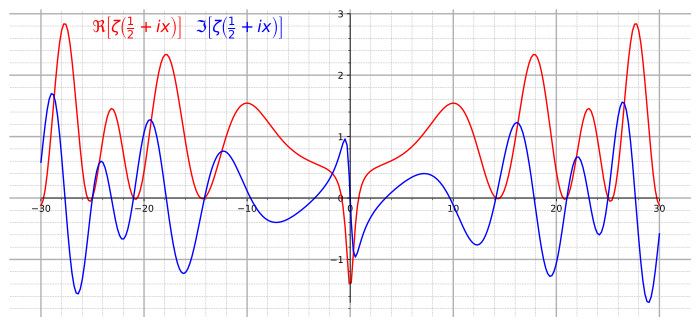




 With the ethical concerns raised by issues of gene editing of human embryos, academic ethics research has set the foundation for and discussed the bioethical threats mankind faces. Alongside artificial intelligence (AI) and similar issues such as data science privacy and the power of social media, the steps into baby manufacturing are illustrated through a mix of modernist and postmodernist ideologies and require a revised notion of a biological-digital autonomy that can account for the changing self. The CRISPR-Cas9 gene editing technology have already shocked and disgusted scholars in science and philosophy around the world. Questions of how much of who we are we should be able to change and what we should do with the rapid power of artificial intelligence on the horizon have taken center stage. With the newfound metamodernism appraoch to science, reality, and existence, we step into gene editing the same way we jump off the deep end of a lake and hold our breath until we rise to the surface.
With the ethical concerns raised by issues of gene editing of human embryos, academic ethics research has set the foundation for and discussed the bioethical threats mankind faces. Alongside artificial intelligence (AI) and similar issues such as data science privacy and the power of social media, the steps into baby manufacturing are illustrated through a mix of modernist and postmodernist ideologies and require a revised notion of a biological-digital autonomy that can account for the changing self. The CRISPR-Cas9 gene editing technology have already shocked and disgusted scholars in science and philosophy around the world. Questions of how much of who we are we should be able to change and what we should do with the rapid power of artificial intelligence on the horizon have taken center stage. With the newfound metamodernism appraoch to science, reality, and existence, we step into gene editing the same way we jump off the deep end of a lake and hold our breath until we rise to the surface. Society and individuals have been shifting from postmodernism into metamodernism. We create the self as something between a postmodernist and modernist notion of reality through gene editing. As opposed to postmodernist traditions that nothing is real and modernist ones that reality is there beyond media, language, and symbols, right now we’re sure reality is somewhere in the middle in our notions of metamodernism. We are both a modernist believer in the power of science and technology and a postmodernist skeptical of the reality we find.
Society and individuals have been shifting from postmodernism into metamodernism. We create the self as something between a postmodernist and modernist notion of reality through gene editing. As opposed to postmodernist traditions that nothing is real and modernist ones that reality is there beyond media, language, and symbols, right now we’re sure reality is somewhere in the middle in our notions of metamodernism. We are both a modernist believer in the power of science and technology and a postmodernist skeptical of the reality we find.  human-like, our autonomy should reflect how the self has been changing through these innovations. The self can be changed artificially much the same way robots and computers are programmed, but they’re not completely fragmented that humans share nothing with one another. These stem cell methods can give humanity a more unified individualistic self that, when appropriately regulated, allow for even modified individuals to exercise appropriate rights and responsibilities. Greely’s ideas still disgust by suggesting market-driven factors to influence human reproductive choices. The principles that doctors and scientists must stand upon are far too likely to become cold, calculated treatments for dehumanized problems. Professor of public health Annelien L. Bredenoord and professor of bioethics Insoo Hyun argued in “Ethics of stem cell‐derived gametes made in a dish: fertility for everyone?” multiplex parenting will shake the very notions of responsibility and autonomy and moreso than other reproductive techniques. They will disgust individuals, citing ideas of the reaction by professor of philosophy Martha Nussbaum’s book Hiding from Humanity: Disgust, Shame, and the Law. Phyisican Leon Kass noted there is wisdom in this repugnance in his paper “The Wisdom of Repugnance: Why We Should Ban the Cloning of Humans.” No amount of sociological or psychological research into the well-being of multiplex children can prevent this natural sense of disgust that we feel at this idea – and with good reason. We must hold onto this disgust and other aesthetic, physiological responses and assess them to the extent which they provide us with moral clarity. From there, a metamodernistic view of gene editing can take place. Writer Carl Zimmer noted in She Has Her Mother’s Laugh that he doesn’t make ethical judgments about multiplex parenting, but “informed consent” in such cases can difficult to determine.
human-like, our autonomy should reflect how the self has been changing through these innovations. The self can be changed artificially much the same way robots and computers are programmed, but they’re not completely fragmented that humans share nothing with one another. These stem cell methods can give humanity a more unified individualistic self that, when appropriately regulated, allow for even modified individuals to exercise appropriate rights and responsibilities. Greely’s ideas still disgust by suggesting market-driven factors to influence human reproductive choices. The principles that doctors and scientists must stand upon are far too likely to become cold, calculated treatments for dehumanized problems. Professor of public health Annelien L. Bredenoord and professor of bioethics Insoo Hyun argued in “Ethics of stem cell‐derived gametes made in a dish: fertility for everyone?” multiplex parenting will shake the very notions of responsibility and autonomy and moreso than other reproductive techniques. They will disgust individuals, citing ideas of the reaction by professor of philosophy Martha Nussbaum’s book Hiding from Humanity: Disgust, Shame, and the Law. Phyisican Leon Kass noted there is wisdom in this repugnance in his paper “The Wisdom of Repugnance: Why We Should Ban the Cloning of Humans.” No amount of sociological or psychological research into the well-being of multiplex children can prevent this natural sense of disgust that we feel at this idea – and with good reason. We must hold onto this disgust and other aesthetic, physiological responses and assess them to the extent which they provide us with moral clarity. From there, a metamodernistic view of gene editing can take place. Writer Carl Zimmer noted in She Has Her Mother’s Laugh that he doesn’t make ethical judgments about multiplex parenting, but “informed consent” in such cases can difficult to determine.