Tag: Science
-
Appearing suspicious may come at a cost

Suspicion by Gültekin Bilge How do you trust others? What makes you become suspicious when working with other people? Though we rely on collecting information about others when making decisions, the ways we collect that information may change how others perceive us. People may be less likely to trust others when they inquire about their behavior in a way that appears suspicious, a new study shows.
Decisions of whether to trust other people can vary based on risk and uncertainty. In simulating how people trust one another using a game between trustees and investors, researchers studied social context, monetary cost, and the trustee’s trustworthiness to show that an investor appearing suspicious may lessen trust and appearing averse to betrayal, increase trust.
Using computational models of how individuals collecting information before making an investment decision, the researchers examined the intuitive patterns behind why participants made the decisions they did. They tested participants under conditions of whether collecting information cost money and whether the trustee would know the investor was collecting information. Participants gathered less information when it came at a cost and when they could find conclusive results from the information about others.
The researchers tested various model to determine which one fit the experimental results best. When the difference between outcomes that would favor investing was different enough from those that wouldn’t, participants stopped collecting information. To test how strong of a role suspicion played in these decisions, they compared the Cost of Appearing Suspicious (CAS) model against a Sample Cost model, an Uncertainty model, and a discrete Drift Duffusion Model (dDDM). For the CAS, Sample Cost, and Uncertainty models, the participants’ decisions are Bayesian in the sense they determined how likely they are to invest based on their previous beliefs about either the trustee or the investor.
The CAS model used a suspicion factor, that gathering information decreases the probability of investment. The Sample Cost model does not use this suspicion factor, and, under the Uncertainty model, participants would stop when the posterior belief distribution width dropped below a tolerance threshold. Under the dDDM, on the other hand, participants would collect information until their evidence for trustworthiness or untrustworthiness met a certain criteria. After determining how well models fit various conditions on the individual level, they found the CAS model predicted better than the others, and it even fit well to investment decisions after collecting information.
When individuals choose to invest or not, scientists have proposed various models for decision-making across different contexts. They come into play as people choose whether to work with or trust others. One study in the Proceedings of the National Academy of Sciences showed, when people work together, they care about whether their partner gathers information about how much they would profit if they defected. They instead engage in blind cooperation cooperate among trustworthy and untrustworthy people, but don’t collect information to make themselves appear suspicious. This is further shown that people are perceived as selfish when they gather information for their own profit in a study in the Journal of Behavioral and Experimental Economics.
The work has practical applications in information collection and use for psychiatric disorders. Biases in collecting information when information is uncertain or scarce has been associated with weighing negative information heavily in depression and compulsivity. How well we model the moral character of other individuals are central to disorders like borderline personality disorder and autism.
-
How the brain makes things simple
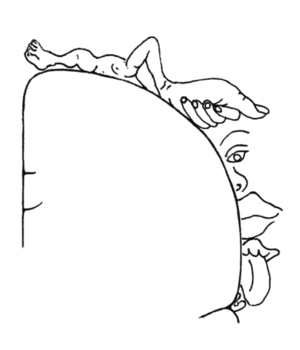
The homunculus depicts how the body represents itself in the somatosensory cortex of the brain. Physical tasks the may seem basic to humans can be much more complicated for machines. The sheer number of degrees of freedom and dimensions the brain must use to make something as versatile and complex as hand motions means that the brain must reduce these high-dimensional spaces to achieve these feats of motion. This is a method of taking complicated processes such as the movement of individual fingers and finding ways of classifying these movements so that they may be accessed without as much information as they would otherwise take. Computational neuroscientists Yuke Yan and James G. Goodman along with biologist Sliman J. Bensmania observed the musculoskeletal movements of human and monkey hand kinematics during sign language, typing, and grasping objects with a principal component analysis. This let them figure out how the motions were specific to certain conditions such as the object trapped or the letter signed using linear discriminate analysis to classify different conditions.
They removed components in descending order of variance by reconstructing the hand posture on each trial and classified them using linear discriminant analysis to determine how many experimental results could be classified correctly. This let them determine the functions of complicated hand gestures using a small number of variables that represent the various motions. Using combinations that account for the motions, this would let researchers understand how such intricate, complicated motions can be governed by a set of neurons or neurophysiological mechanisms. They tested how similar the results were between humans and monkeys and found monkeys had hand postures that weren’t as specific for different objects.
Finally the researchers classified hand motions using spike counts of neurons in the primary motor cortex to determine which ares of the brain corresponded with different motions. This gave them an overarching picture from neuroscience to behavior in how the brain makes sense of complicated, concerted movements.
Other methods of taking advantage of the probability let scientists create maps that can measure across variables in space. One may use a stochastic process, a family of random variables, on a space of probabilities to choose appropriate parts of the space that correspond with different outcomes. This can be applied from simple axon models of individual neurons to entire neural networks.
Very little is known about exactly how the brain interprets somatosensory activity as a particular tactile sensation. Some initial evidence towards understanding this comes from individuals with brain damage due to stroke. Researchers studying the somatosensory cortex of the brain, the part linked with tactile localization, have shown that hands and forearms tend to mislocalize sensations of touch towards their centers in healthy individuals and those who have had strokes in somatosensory regions. Psychologists Janellen Huttenlocher and Susan Duncan and statistician Larry Hedges proposed that spatial locations bias towrds the middle of categorical spaces and away from boundaries the more uncertain their information is. This method of dealing with uncertainty is another example of how the brain simplifies problems when it needs to.
Flies and humans use coding strategies when processing visual information to create more-refined images. Fly and cone photoreceptors respond to light by adapting their gain to a local mean intensity. This creates a contrast between intensity at the receptor and the local mean. The receptors then code the response to this contrast among all the values of input light. This way, the nervous system simplifies intensities to proportions that are more easily evaluated by the neuron’s response range. It also lets the fly or human identify same objects under different lighting.
-
A machine learning approach to Traditional Chinese Medicine
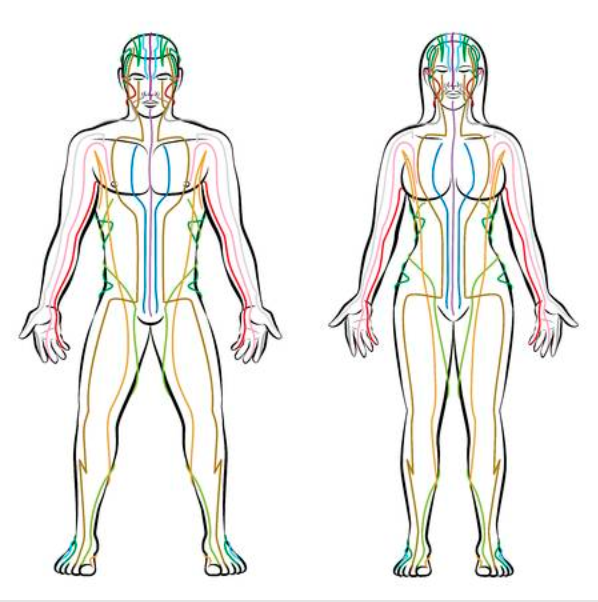
Modern science can uncover ancient wisdom. While it may seem regressive or pseudoscientific to study concepts from Traditional Chinese Medicine (TCM), they reveal deeper meanings about who we are as humans when subject to scrutiny by the scientific method. The herb formulas, plant-derived nature produces of TCM are still used in disease prevention and treatment despite the dominance of modern science. When medical researchers performed machine learning classification methods on 646 herbs are according to organ systems, known as Meridians, they found the 20 molecule features were most important for predicting these Meridian. It included structure-based fingerprints and properties of absorption, distribution, metabolism, and excretion. As the first time molecular properties of herb compounds have been associated with Meridians, this provides molecular evidence of Meridian systems.
The Meridian system dictates how he life-energy qi flows through the body. Qi includes actuation of the body, warming, defense again excess, containment of body fluids, and transformation between qi and food, drink, and breath. Each Meridian corresponds to a yin yang quality, an extremity (hand or foot), one of the five elements (metal, fire, earth, wood, or water), an organ (such as heart or kidney), and a time of day. The yin yang qualities describe how complementary, opposite forces of the universe interact, such as Greater Yin or Lesser Yang. Given these roots in traditional, non-scientific thought, scholars have debated the scientific justification behind why and how TCM works. In their paper “Predicting Meridian in Chinese Traditional Medicine Using Machine Learning 2 Approaches,” the researchers assumed Meridian can be found through scientific methods to begin with. The five elements are qi are metaphysical, not modern physiological or medical phenomena. The researchers emphasized the need to examine the herb medicine actions as they relate to disease etiology to create a formal understanding of TCM.
Qi and yin yang as they relate to human health date back to texts of discussion and debates from the Warring States period (475–221 BC) of ancient China. Philosopher Zhaunghzi noted qi was the basis of the body’s physical being with the six qi (wind, cold, summer heat, fire, dryness, and damp) in harmony with one another as they affect the seasons. These theories would be used in medicine to describe relations and analogies between the body, the state, and the cosmos, or the universe.
-
The neuroscientific basis of consciousness

Part of “Furious Dreams” by Marc Garrison Scientists and philosophers alike have examined and pondered about consciousness, one of the most central problems in our experience of the world. Both approaches may seek different methods, with science being empirical and philosophy, speculative, but they’re both relevant to any discussion on such a complicated phenomena. Understanding how neural correlates of conscious experience correspond to various parts in the brain lets scientists take “bottom-up” approaches of beginning with empirical phenomena and determining what cognitive and psychological behaviors result. On the other hand, beginning with the philosophy of mental states, including beliefs, intents, desires, emotions, knowledge, and figuring out how those can be attributed to the mind moves in the opposite direction. These mental states are whatever is the nature of the mental phenomena the mind occupies. It’s the way the brain makes sense of the world. A combination of empirical neural data from both computational and psychological models alongside a philosophical analysis would let us bridge the gap between the brain and consciousness. Either way, researchers end up with a neurobiologically accurate view of the brain in how consciousness emerges. There are many challenges to neuroscience explaining consciousness and its findings have philosophical significance to many ideas in epistemology, ethics, and metaphysics.
The difficulty of the subjective experience presents a challenge to consciousness. Any person’s experience is an external phenomena to anyone else. Philosopher Edmund Husserl’s notions of phenomenological and natural attitude show this relationship between the first- and third-person experiences. When someone perceives a car, their consciousness is directed at the car and that person is not necessarily aware of the details of the experience, such as what the steel car feels like. This is Husserl’s natural attitude. When that person focuses on the experience of perceiving the car as its own experience, it is a phenomenological attitude. A neuroscientist would generally concern themselves with the external phenomena they research and endorse the natural attitude. But the concepts of a scientific model (such as water being composed of two hydrogen atoms and one oxygen) are conscious phenomena a neuroscientist uses to understand the model. The neuroscientist can use the phenomenological attitude towards those models as experiences, and this shows we can’t escape our own point of view. Even a scientific model is a representation in one’s mind.
Consciousness as a neuroscientific phenomena requires a study of this relationship between an experience and the scientific model of it. The gap between the two can depend upon whether one endorses a realism view of science or an antirealism one. Under realism, mature scientific theories can be true and describe the world such that the gap is non-existent or narrow. Scientific realism means that all natural phenomena can be modeled using the structures and relations among them. We may model qualitative feelings, or qualia, our subjective experiences, using these structures and relations. It still leaves certain experiences difficult, such as how one may see the color red as a structural relationship given that introspection about redness doesn’t reveal its nature. Anti-realism, on the other hand, dictates we can only say whether a neuroscientific theory of consciousness is compatible with observations, not whether it captures nature. There is a large epistemic gap between any concrete phenomenon and the corresponding scientific models. The experiences are not different in this respect.
Before the 20th century difference between philosophy and science, philosophers generally studied consciousness through both philosophical and scientific means. French philosopher René Descartes performed research in mathematics, neuroscience, and philosophy. Psychologist-philosopher William James would create philosophical theories in light of empirical psychology research. With the rise of logical positivism, the idea that only statements that can be empirically verified are meaningful, in the early 20th century, philosophers focused on the semantic content of arguments instead of empirical scientific results. During this time, the three traditional perspectives of the mind-brain question, physicalism, mentalism, and dualism, emerged. Physicalism is the thesis that everything can be reduced to physical phenomena, mentalism, to mental phenomena, and dualism, that everything is either mental or physical. he rise of physicalism in the late 19th century meant to take consciousness as unscientific in some interpretations. Philosopher Galen Strawson’s realistic physicalism means the physical nature of the nervous system can manifest consciousness through mental activity. This can be illustrated with an example of philosopher Frank Jackson’s knowledge argument.
The argument uses the fictional story of a famous neuroscientist Mary who learns everything about the world through a computer but remains confined to a room that is entirely black and white. If physicalism were true, one might argue Mary knows everything about the world, but, because she has not experienced color, she does not know what it is. Upon seeing color, this argument would dictate that she would experience a subjective experience of her consciousness that she had never encountered before and, therefore, learns something new – showing she did not know everything about the world. One may conclude, from this line of reasoning, physicalism doesn’t entail everything. Possible responses to this may include the ability hypothesis – that Mary learns how to see color, but doesn’t learn what color is, therefore, what she learns doesn’t contradict that she knew everything about what the world was.
The historical trends meant changes, not only for consciousness, but for science as a whole. Scientific terms began taking new meanings. With the rise of thermodynamics around the turn of the 20th century, heat went from meaning boiling water to a specific dimension of temperature variation. Consciousness became an empirical phenomena of brain activity variation.
Consciousness presents researchers with the problem of how to explain when a mental state is conscious rather than not as well as what the content of a conscious state is given the subject experience of everyone’s consciousness. From a philosophical perspective, we rely instead on behavior and introspective testimony on the nature of consciousness in searching for common features from which we deduce knowledge about consciousness. From the neuroscientific angle, we study the central nervous system and the neural properties in the cerebral cortex. Psychologists Jussi Jylkka and Henry Railo have argued scientific models of consciousness need to explain consciousness’ constituents, contents, causes, and causal power. Though consciousness has many aspects to it, we focus on perception in this essay. Consciousness can further be differentiated into phenomenal consciousness, the properties of experience that correspond to what it’s like to have those experiences, and access consciousness, consciousness based on which states one can access.
The global neuronal workspace explains when a mental state is in consciousness such that it is accessible to systems related to memory, attention, and perception. Accessing content means it can use its content in performing computations and processing. Consciousness resides in these accessed states by the cortical structure of the brain that is involved with perceptual, mnemonic, attentional, evaluational and motoric systems. Whatever neurons are involved in someone’s current state constitute the workspace neurons. They activate such that the neural activation causes activity between workspace systems. It’s tempting to say the cortical workspace network correlates with the phenomenon of consciousness itself especially given imaging results can show which areas of the brain activate when a subject is conscious, but this correlation doesn’t tell us whether brain activity is of phenomenal or access consciousness.
Another approach, recurrent processing theory, ties perceptual to processing consciousness without a workspace and, instead, a focus on activity connecting sensory areas of the brain. It uses first-order neural representation, that we may perceptually represent the content of a mental state to mean perceiving that content, to explain consciousness. Interconnected sensory systems may use feedforward and feedback connections, such as those in the first cortical visual area, V1, which carry information to higher-level processing areas. The forward sweep of processing uses feedback connections linking visual areas. Global workspace theory and recurrent processing theory differ in the stages of visual processing they depend upon. The four stages of visual processing are superficial feedforward processing (process visual signals locally in the visual system), deep feedforward processing (the signals can influence action), superficial recurrent processing (information travels to previously visited visual areas), and widespread recurrent processing (across broad areas such as the global workspace access). Recurrent processing at the third stage, superficial recurrent processing, is necessary and sufficient for consciousness according to recurrent processing theory, and at the fourth stage, widespread recurrent processing, for the global workspace theory.
Philosopher Victor Lamme has argued that superficial recurrent processing is sufficient for consciousness because features of widespread recurrent processing are also found in superficial recurrent processing. Recurrent processing is found in both stages, and the global neuronal workspace theory allows superficial recurrent processing to correlate with widespread processing. Lamme believes that, in response to visual stimuli, there is first a fast forward sweep of processing, proceeding through the cortex. This first stage is nonconscious. Only a second stage of recurrent processing, when earlier parts of the visual cortex are activated once more by feedback from later parts, is taken to be conscious (with, again, empirical support).
Another approach to consciousness holds that one can be in a conscious state if and only if one represents oneself in that state. If one were in a conscious visual state of seeing am moving, that person must represent themselves in that visual state. The higher-order state represents the first-order state of the world and results from the consciousness of the first-order state. One must be aware of a conscious state to be in it. This lets neuroscientists correlate empirical work on higher-order representations of states with prefrontal cortex activity. For some higher-order theories, one can be in a conscious state by representing oneself even if there is no visual system activity.
Neuroscientists can use empirical tests of higher-order theory against other accounts, but neurologist Melanie Boly has argued that individuals with the prefrontal cortex removed can still have perceptual consciousness. This may prefrontal cortical activity isn’t necessary for consciousness, but one may argue the experiments didn’t remove all of the prefrontal cortex or that the prefrontal cortex is necessary, but in a more complicated system than previously suggested. Psychologist Hakwan Lau and philosopher Richard Brown have used experimental results to suggest consciousness cannot exist without the corresponding sensory processing as predicted by some higher-order accounts.
Finally, the Information Integration Theory of Consciousness (IIT) uses integrated information to explain whether one is in a state of consciousness. Integrated information is the effective information parts of a system carry in light of the causal profile of the system. If the information a system carries is greater than the sum of the information of each of the individual parts, then the information of that system is integrated information. IIT holds that this integrated information implies that a neural system is consciousness, and, the more integrated information there is, the more conscious the system is. Neuroscientist Giulio Tononi has argued the cerebellum has a low amount of consciousness compared to the cortex as it has far fewer connections even though it has more neurons. IIT suffers from treating many things as conscious even when they don’t seem to be. Tononi has proposed that a loop connecting the thalamus and cortex forms a dynamic core of functional neural clusters, varying over time. This core is assumed to integrate and differentiate information in such a way that consciousness results.
Neuroscientist J. H. van Hateren has presented a computational theory of consciousness in which the neurobiology of the brain allows it to compute a fitness estimate by a specific inversion mechanism that also causes the feeling of consciousness. His conjecture that consciousness is a transient and distinct cause the individual produces when he or she prepares to communicate—externally or internally. Citing the thalamocortical feedback loop, the internal variables involved in this process estimate the individual’s evolutionary fitness.
Despite how flashy it sounds to say researchers can completely understand consciousness, the challenges that neuroscientists and philosophers face mean things are far from completely figured out. There remains a lot to be discovered and examined from both scientific and philosophical angles.
-
A metamodernist narrative of genetic engineering

 With the ethical concerns raised by issues of gene editing of human embryos, academic ethics research has set the foundation for and discussed the bioethical threats mankind faces. Alongside artificial intelligence (AI) and similar issues such as data science privacy and the power of social media, the steps into baby manufacturing are illustrated through a mix of modernist and postmodernist ideologies and require a revised notion of a biological-digital autonomy that can account for the changing self. The CRISPR-Cas9 gene editing technology have already shocked and disgusted scholars in science and philosophy around the world. Questions of how much of who we are we should be able to change and what we should do with the rapid power of artificial intelligence on the horizon have taken center stage. With the newfound metamodernism appraoch to science, reality, and existence, we step into gene editing the same way we jump off the deep end of a lake and hold our breath until we rise to the surface.
With the ethical concerns raised by issues of gene editing of human embryos, academic ethics research has set the foundation for and discussed the bioethical threats mankind faces. Alongside artificial intelligence (AI) and similar issues such as data science privacy and the power of social media, the steps into baby manufacturing are illustrated through a mix of modernist and postmodernist ideologies and require a revised notion of a biological-digital autonomy that can account for the changing self. The CRISPR-Cas9 gene editing technology have already shocked and disgusted scholars in science and philosophy around the world. Questions of how much of who we are we should be able to change and what we should do with the rapid power of artificial intelligence on the horizon have taken center stage. With the newfound metamodernism appraoch to science, reality, and existence, we step into gene editing the same way we jump off the deep end of a lake and hold our breath until we rise to the surface.The oft-repeated truism “science is moving so fast that ethics just can’t keep up” couldn’t be farther from the truth. Ignoring the baseless assumption that science and ethics were racing against one another, the scientistic idea that philosophers and ethicists in similar fields have not addressed the power and potential of science would be to disregard the decades of ethics research on genetic engineering. The claim also seems to treat science as an uncontrollable force that must be braced against because we can’t do anything to stop it. It’s false that mankind has complete control over nature, but the notion inaccurately portrays mankind as weak and vulnerable to the world when we can take a metamodernist approach that rests somewhere in between. Researchers in ethics have been paying close attention. They’ve been studying everything closely.
 Society and individuals have been shifting from postmodernism into metamodernism. We create the self as something between a postmodernist and modernist notion of reality through gene editing. As opposed to postmodernist traditions that nothing is real and modernist ones that reality is there beyond media, language, and symbols, right now we’re sure reality is somewhere in the middle in our notions of metamodernism. We are both a modernist believer in the power of science and technology and a postmodernist skeptical of the reality we find. Genetic engineers have begun using pluirpotent stem cells, ones that have the same properties of embryonic stem cells but come from manipulating ordinary adult cells rather than destroying embryos, that are more effective in providing dozens or hundreds of offspring for individual parent cells. As more stem cell research goes into how male sex cells can result from female cells and vice versa, this could even allow single parents or same-sex couples to produce biological children. Researchers have even predicted scenarios in which children result from the DNA of more than two biological parents, known as “multiplex parenting.”
Society and individuals have been shifting from postmodernism into metamodernism. We create the self as something between a postmodernist and modernist notion of reality through gene editing. As opposed to postmodernist traditions that nothing is real and modernist ones that reality is there beyond media, language, and symbols, right now we’re sure reality is somewhere in the middle in our notions of metamodernism. We are both a modernist believer in the power of science and technology and a postmodernist skeptical of the reality we find. Genetic engineers have begun using pluirpotent stem cells, ones that have the same properties of embryonic stem cells but come from manipulating ordinary adult cells rather than destroying embryos, that are more effective in providing dozens or hundreds of offspring for individual parent cells. As more stem cell research goes into how male sex cells can result from female cells and vice versa, this could even allow single parents or same-sex couples to produce biological children. Researchers have even predicted scenarios in which children result from the DNA of more than two biological parents, known as “multiplex parenting.”Recent success in both cloning and CRISPR technologies have let scientists understand better the embryology and developmental physiology of human embryos as a result of the pluripotent stem cell advancements and in vitro fertilization (IVF). We must warn of the issues that may arise as stem cell reproduction methods gear towards manufacturing embryos for desirable traits. Couples who choose to keep their unwanted embryos frozen or donate them to further research or to other couples need to be aware of how those embryos are being used to assess their role of responsibility in stem cell research.
This stem cell method comes with the advantage as the daughter cells result similar to the adult ones, and researchers have posed solutions for the issues of eugenic control that would result. We can critique these ideas for their shortcomings in characterizing the eugenics movement. These movements do not thoroughly emphasize the social forces governing how individuals would be manufactured. To address the issues raised by gene editing, we need a deeper, more multidimensional view of the moral problems raised by eugenic control that accounts for the changing self and reality in a metamodernist world. We can engage in these subjects through personal narratives and humanized ideas of who we are that embrace ethics and threats of existentialism.
Researchers have, however, brought up solutions that derive from dangerous principles of eugenics and extreme notions of individual autonomy. In the transition to metamodernism, they prevent mankind from pushing back against looming threat of a full-fledged surveillance state, and, instead disregard the idea that a particular line of research can be inherently morally wrong. These transhumanist thinkers such as philosopher Nick Bostrom (who has also warned about the threat of Superintelligence) who proposes a solution to use stem cell sex cells for performing eugenic selection for intelligence, partially as a method for combating superintelligent AI. If humans can replicate natural selection on a group of embryos over the course of several generations, they can produce the most intelligent humans possible. This eugenics approach isn’t uncommon, either. Ethics professor Nicholas Agar wants prospective parents to choose how they can improve their children in a “liberal eugenics” fashion. This sort of scientific perfection fails to capture how these humans would supposedly relate to the rest of society given that they’ve attacked the fundamental ideals of community and sharedness that humans share. Bostrom does suggest there may be religious or moral grounds to prohibit this method of creating genetically enhanced children, but claims having children at a disadvantage to those around them would cause everyone to eventually pick up the technique. This reasoning rests on a dangerous egalitarian notion of human success and morality driven by competition in a way that forces those who disagree to accept the technique. It doesn’t rest upon morally reasoned principles or the virtues of humanism and research. Much the same way individuals would rapidly evolve under Bostrom’s scheme, the entirety of society should follow suit regardless of choice.
Bostrom’s idea also doesn’t recognize the reality of how natural selection and evolution work. Much like natural selection, this method wouldn’t automatically and instantly choose the most optimal DNA. Instead, it would choose a heritable trait without regard to DNA the same way nature influences which traits are optimal for survival and reproduction. Bostrom’s method relies on knowing which parts of the DNA are responsible for the trait which can be edited directly without the need for cycling through generations. Besides, the genetic basis for these traits have been shown to be limited as the traits themselves are a complicated amalgamation of environmental interactions, genetic pathways, what epigenetic factors activate throughout an individuals’ lifetime, how nature would “select” for certain traits, and the resulting phenotypes. It wouldn’t dictate how a superintelligent human may emerge. The typical issues of the artificial selection process being prone to error and having an inherent natural selection to it raise concerns as well. All of this lies on the inhumane assumption that we may find human perfection through genes regardless of how an objectified individual may control their own fate and what right they have to do so. Indeed, the vacuous claim that “science is moving so fast that ethics just can’t keep up” only measures unethical, unjustified notions of how fast science is moving to begin with.
The ethics of some reproductive technologies become blurrier in light of the newly complex understanding of heredity’s cross-currents. A maternal surrogate, for example, will likely exchange stem cells with the fetus she carries, opening the door to claims that baby and surrogate are related. If the surrogate later carries her own baby, or that of a different woman, are the children related? Parenthood becomes even stranger with so-called mitochondrial-replacement therapy. If a woman with a mitochondrial disorder wants a biological child, it is now possible to inject the nucleus of one of her eggs into a healthy woman’s egg (after removing its nucleus), and then perform in vitro fertilization. The result is a “three-parent baby,” the first of which was born in 2016. Zimmer doesn’t presume to make ethical judgments about procedures such as this, but warns that “informed consent” in such cases can be unexpectedly difficult to determine.
The more honored individuals in bioethics such as Stanford law professor Henry Greely have voiced similar arguments. Greely has argued insurance companies and government agencies can help fund the effective DNA sequencing methods in fighting genetic disease. In his book The End of Sex and the Future of Human Reproduction, he predicts how we may perceive and judge the potential of stem cell technologies. He notes he wouldn’t ban embryos created from a single parent, but would still require pre-implamentation genetic diagnosis to select for optimal offspring. But, above all, Greely emphasizes that these should be closely scrutinized by a standing commission that can recognize what principles all people would believe in. What sort of principles all individuals would agree upon, such as the four common principles of medical ethics: autonomy, beneficence, non-maleficence, and justice, are up for debate. The principles of parenthood should be upheld even for extreme scenarios of the future that may select for the most desirable traits such that biological parenthood becomes meaningless. We must protect every notion of humanity that comes from our current methods of reproduction, both biologically and artificially, to address these issues.
With the growing threat of AI, namely that computers may become more and more
 human-like, our autonomy should reflect how the self has been changing through these innovations. The self can be changed artificially much the same way robots and computers are programmed, but they’re not completely fragmented that humans share nothing with one another. These stem cell methods can give humanity a more unified individualistic self that, when appropriately regulated, allow for even modified individuals to exercise appropriate rights and responsibilities. Greely’s ideas still disgust by suggesting market-driven factors to influence human reproductive choices. The principles that doctors and scientists must stand upon are far too likely to become cold, calculated treatments for dehumanized problems. Professor of public health Annelien L. Bredenoord and professor of bioethics Insoo Hyun argued in “Ethics of stem cell‐derived gametes made in a dish: fertility for everyone?” multiplex parenting will shake the very notions of responsibility and autonomy and moreso than other reproductive techniques. They will disgust individuals, citing ideas of the reaction by professor of philosophy Martha Nussbaum’s book Hiding from Humanity: Disgust, Shame, and the Law. Phyisican Leon Kass noted there is wisdom in this repugnance in his paper “The Wisdom of Repugnance: Why We Should Ban the Cloning of Humans.” No amount of sociological or psychological research into the well-being of multiplex children can prevent this natural sense of disgust that we feel at this idea – and with good reason. We must hold onto this disgust and other aesthetic, physiological responses and assess them to the extent which they provide us with moral clarity. From there, a metamodernistic view of gene editing can take place. Writer Carl Zimmer noted in She Has Her Mother’s Laugh that he doesn’t make ethical judgments about multiplex parenting, but “informed consent” in such cases can difficult to determine.
human-like, our autonomy should reflect how the self has been changing through these innovations. The self can be changed artificially much the same way robots and computers are programmed, but they’re not completely fragmented that humans share nothing with one another. These stem cell methods can give humanity a more unified individualistic self that, when appropriately regulated, allow for even modified individuals to exercise appropriate rights and responsibilities. Greely’s ideas still disgust by suggesting market-driven factors to influence human reproductive choices. The principles that doctors and scientists must stand upon are far too likely to become cold, calculated treatments for dehumanized problems. Professor of public health Annelien L. Bredenoord and professor of bioethics Insoo Hyun argued in “Ethics of stem cell‐derived gametes made in a dish: fertility for everyone?” multiplex parenting will shake the very notions of responsibility and autonomy and moreso than other reproductive techniques. They will disgust individuals, citing ideas of the reaction by professor of philosophy Martha Nussbaum’s book Hiding from Humanity: Disgust, Shame, and the Law. Phyisican Leon Kass noted there is wisdom in this repugnance in his paper “The Wisdom of Repugnance: Why We Should Ban the Cloning of Humans.” No amount of sociological or psychological research into the well-being of multiplex children can prevent this natural sense of disgust that we feel at this idea – and with good reason. We must hold onto this disgust and other aesthetic, physiological responses and assess them to the extent which they provide us with moral clarity. From there, a metamodernistic view of gene editing can take place. Writer Carl Zimmer noted in She Has Her Mother’s Laugh that he doesn’t make ethical judgments about multiplex parenting, but “informed consent” in such cases can difficult to determine.Reading, learning, and writing about these issues is the first step. For anyone to learn more about science and technology in this age would help spread humanism to fight ignorance. These issues need to enter the sphere of public debate and discussion in contrast to how they’re currently only governed by scientists, ethicists, and philosophers. We need laws in place to prevent these catastrophic consequences long before they occur. In our metamodernist society, we need not reject science and technology entirely. We may remain skeptical of the notions of progress and reality, but only to a point where we can begin a new direction for scientific research. Given the existential crises of genetic engineering and artificial intelligence, we may imagine a moral society through personal development and psychological growth in wrestling with and understanding these struggles. We need a humanized notion of reproduction to address psychological needs of individuals in a society that has the power of gene editing. We can create a grand narrative that mankind has an overarching worldview to connect all humans to one another, but hold it lightly enough to recognize the limits of what we know and should do. We can understand that we may create an idea of “reality” and methods of understanding the world around us that respect scientific research while still questioning the authority of problematic research techniques. By creating a “reality,” we can embrace the truths that we can create a moral society that determines who we are despite the changing self brought upon by genetic engineering and the digital age. We can determine what is honest, authentic, and true without being cynical, showing contempt for the beliefs and sensibilities of others, and turning to eugenics approaches for solutions. Metamodernism, as it begins to infect all areas of life, means our scientific research should seek elegant, morally refined methods that we embrace for knowledge.
Only then will we come closer to our selves in a metamodernist future. The intellectual thought to counter the doomsday dystopia scenarios of the future can involve selecting for desirable traits in offspring through trustworthy, verified methods that acknowledge the rights and responsibilities of the individual. We must remain skeptical of harmful progress, but remain open to gene editing technologies insofar as they may help mankind without raising ethical concerns.
-
Recognition and representation: two faces of the same coin
While humans and computers both have the capacity to recognize faces, pattern recognition problems in computer vision seek to represent data in an appropriate way for the problem to solve. Machine learning methods approach pattern recognition as a statistical problem of searching for patterns in data. Through classifying data into different categories, reducing the data’s dimensions, approximating parts of the data, and other techniques that exploiting geometry, algebra, and other quantitative features of the data, computers can recognize faces, handwriting, images, and other visual stimuli in ways similar to humans.
Neural networks and deep learning methods have had practical applications in fingerprint analysis, disease etiology, and voice recognition, to name a few examples. Artificial intelligence continues to find success in various areas of research. But before computers can behave like humans, they need to represent the world in some way. The way computers interpret input data lets them represent the world.
These representation methods include principal component analysis (PCA), in which eigenfaces estimate variance among data. These eigenfaces, mathematical representations of key features used in human face recognition, are calculated using the the covariance matrix of the probability distribution over the high-dimensional vector space of face images. In other words, they let computers discern basic patterns among images of faces. PCA reveals eigenfaces that correspond to the least-squares solution so that the data variance is maintained while getting rid of existing correlations that don’t contribute to it. Generating eigenfaces involves extracting relevant facial information, through methods like searching for statistical variation between images, and representing them efficienctly, such as through using symmetry or other geometric features. While eigenfaces are automatic and easy to code, especially in how they can make complicated faces simple, they can become very sensitive to external features such as lighting and struggle to provide useful information about the faces themselves.
Other machine learning techniques such as classification find categories to map input data by discriminating between different features and representing those features with their distance from one another depending on their similarity. Fisherfaces, named after statistician Ronald Fisher, result from the basis vectors of a subspace representaiton of face images when performing linear discriminant analysis (LDA). Fisherfaces are less sensitive to lighting issues than eigenfaces and require data built upon continuous independent variables, such as skin tone or shape.
While eigenfaces depend upon PCA to account for data variance, fisherfaces use LDA searches for differences between classes of data. A team lead by computer science professor Peter Belhaumer at Columbia University found lower error rates among fisherfaces than among eigenfaces. In their paper, “Eigenfaces vs. Fisherfaces: recognition using class specific linear projection,” they accounted for variations in lighting and facial expressions. Regardless, researchers in computer vision can use both methods to minimize error when solving problems in recognition and representation.
Both eigenfaces and fisherfaces also struggle in capturing changes in expression and emotion among faces. For researchers in computer vision to approach facial expression analysis means understanding the nuance and complexity of the face. Muscular movements originate in the nerves by the VIIth cranial nerve from the brainstem between pons and medulla. The motor root of the nerve gives somatic muscle fibers to the face that create facial expressions. With enough data and efficient routines, pattern recognition can identify emotions from expressions and determine which parts of the brain may be involved in creating them. Neuroscientists have shown face muscles in lower parts of the face are more represented in the motor cortex which are especially involved in speech. From these patterns from hundreds and thousands of faces, computers may soon be be able to discern function from the form of a face itself.
The seven universal facial expressions of emotion (happy, surprise, sadness, fear, anger, contempt, and disgust) have seven ways to regulate themselves (expression, deamplified, neutralized, qualified, masked, amplified, and simulated). Psychologist Paul Ekman determined these emotions and expressions were universal among humans across different countries and levels of industrialization or development in his manuscripts “A New Pan-Cultural Facial Expression of Emotion” and ” The repertoire of nonverbal behavior: Categories, origins, usage, and coding.” He found that humans produced these expressions in response to similar conditions even regardless of how we may judge a face as expressing a certain emotion. The extent to which the emotions are universal, however, remains up to debate. Ekman supported his work by surveying humans across different civilizations, including tribes in New Guinea, but he argued this non-cognitive component is only a part of emotion. This automatic appraisal detects stimuli almost instantly identify elicitors which then activate the seven universal expressions that further cause the physiological elements of the emotional response. This would include any bodily change such as the feeling of one’s heart dropping, skeletal muscles tightening, facial muscles loosening, changing voice pitch, and other features of the nervous system.
As recognition and representation depend upon one another, neuroscience and artificial intelligence continue to support one another despite their different paths. As expression and emotion intertwine into one another, we create a more nuanced picture of perception that speaks to who we are as humans. While eigenfaces and fisherfaces support similar goals as well, their different methods lets computer vision researchers attend to the variety of challenges deep learning has to offer.
-
Philosophy faculty empower students to tackle ethical issues in data science

How would Aristotle approach Facebook’s methods? The future of data science is a mystery surrounded by concerns about autonomy, responsibility, and other ethical issues related to technology. The recent Facebook-Cambridge Analytica data scandal raised concerns of personal privacy, ethical principles for social media businesses, as well as misinformation.
In his single-credit PHIL 293 course “Ethics for Data Sciences”, assistant professor of philosophy Taylor Davis challenges students to re-think what they believe about morality in the wake of these controversies in science and technology.
In light of advancing technologies in artificial intelligence and machine learning, Davis said it is becoming more clear that ethical training is necessary for data science.
“Broadly what is happening, especially we see Mark Zuckerberg testify in front of Congress, is ethics pervades all of our lives as we become more reliant on it in many ways,” Davis said.
Partnered with the Integrative Data Science Initiative, faculty are planing to make the course three credits with an online version, said Matthew Kroll, post-doctoral researcher in philosophy, and even advance ethics through other initiatives.
“One of the questions I start the class with is ‘What does it mean to be ethical in the age of the big data?’” Kroll said. The students discuss current events like the Facebook Cambridge Analytica data scandal and individuals and organizations should have done.
Kroll has also previously taught the course by giving students a “tool kit” of philosophical methods of reasoning to address these issues as well as concerns of rights and autonomy with respect to artificial intelligence and autonomous cars.
“If you’ve never taken an ethics course, you at least get to dip your toes in the water of what ethics is,” Kroll said.
By teaching students how to form philosophical arguments and put issues in historical perspectives, Kroll hopes to teach students how to make better ethical decisions.
“If these students feel like in their professional lives they reach a moment or a threshold that, if there’s an ethical issue in their workplace like ‘Are we gonna sell data to a particular government interest?’ to at least say ‘I don’t think this is right’ or ‘I think this is an unethical use of user data,’” Kroll said. “If one, two, or three students do that, then I’ll feel like the class is a success.”
Through an applied ethics course, Davis emphasized philosophy runs in the background as he instructs. In contrast to the standard philosophy-based methods of beginning with general, theoretical principles, he delivers current events as case studies.
Davis created the course by substituted data science with engineering from an engineering ethics course.
With a case-study based bottom-up approach, students begin with real world problems then figure out how to reason with those actions in mind. From these methods of isolating actions from agents and forming arguments, they learn how ethical principles such as not causing unnecessary harm to others and respecting personal rights come into play.
Through these methods, students find truth and clarity on tricky issues that they may apply to other problems such as autonomy of self-driving cars and gene editing technologies, Kroll said.
“Machine learning algorithms perform calculations in opaque methods,” Davis said. “They create a complicated model that researchers need to understand.” Davis said this would let researchers determine how to resolve social inequality issues related to women and minorities or forming predictions on individual habits. He wants students to consider how similar people are to robots that may perform human-like actions and how that raises issues about personal agency.
“The idea is to give people that kind of training to see and identify ethical issues,” Davis said.
Students will continue to grapple with what it means to be human in the “age of big data”, Kroll said. “The ethics in data science instruction serves to empower students in their future careers.”
-
Digital Divide Index measures economic disparities across Indiana
The lack of high-speed internet access in Indiana’s rural areas means limited access to educational and employment opportunities. Robert Gallardo, a community regional economics specialist at Purdue University, wants to fix that.
Sixteen percent of Hoosiers live without broadband internet access, down 2% since 2017, according to the advocacy website, BroadbandNow. The Southeastern Indiana Regional Planing Commission (SIRPC) 2019 “taste of Broadband” report revealed more than 90 percent of residents in Franklin and Switzerland counties do not use 25 Mbps and Ohio County has the highest property info households without computing devices at 22.3 percent.
This is partly due to the work of Gallardo, including how he and a team of researchers created the Digital Divide Index (DDI) to quantify these disparities. Ranging from 0 to 100, with 100 indicating the largest digital divide, the DDI quartiles showed the highest disparities among west, south, and southwest counties, according to the Digital Divide in Indiana report published by Gallardo and other researchers. Meanwhile, the smallest divides were located in the northwest and central counties.
Composed of scores measuring the infrastructure and adoption of broadband and the socioeconomic characteristics that effect technology adoption, the DDI can differnetiate 25/3 access and internet sped the former category and educational level, poverty rate, and elderly or disabled population in the latter.
The report found greater decreases in working age population of counties with the highest DDI when compared with the state and national averages over the course of 2010 to 2015. These counties also experienced smaller increases in the number of jobs and estbalishments.
As the 25th most connected state, according to BroadbandNow, there are 237 internet providers in Indiana. Some 757,000 people in Indiana do not have access to a 25 Mpbs wired connection. Bridging the digital divide means using the DDI statistic to understand disparities in the state, Gallardo says.
That is a problem holding the state back, Gallardo says. Providing broadband internet access to all ares of Indiana, he says, woods provide individual with equal access to a global economy. It also would give communities the ability to communicate and work with more commercial and residential developers throughout the entire state. It would improve the quality of life for the residents affected and, as technology advances, give everyone equal access to opportunities.
Understanding how internet access affects the nation as a whole means defining the nature of internet speeds. I n2015, the Federal Communications Commission rose the minimum of what qualifies as broadband service. The agency voted to raise the download speed threshold from 4 megabits per second (Mbps) to 25 Mbps and upload speed from 1-3 Mbps. The nation recognizes this “25/3” speed as broadband speed.
Gallardo said over the past few years, researchers have gained access to granular data – data that can be divided and analyzed for the most basic feathers. He has described how the broadband infrastructure in Indiana continues to improve. He has stressed the importance of putting data in context and coming up with ways to cross-check and validate what the data means.
Gallardo said he hopes the work can create more consistent and widespread resources as the SIRPC report found 45% of individuals did not have access to internet for five or more days due to unpaid bills, broken devices, or similar reasons due to lack of resources.
“We’re trying to translate that data where it can be used for meaningful discussions,” Gallardo said. “This report is crunch gin all these numbers just so that you and I in the region can say, ‘OK, what can we do about it?’”
In 2014, 83 percent of housing units in Indiana had access to the 25/3 broadband standard. That percentage is now at 90.4 percent, but Gallardo warned there are statistical shortcomings in the ways these data are collected such that they have not been appropriately validated.
“The problem with that dataset is that it’s user-provided,” Gallardo said, “not checked by a federal agency.”
Susan Craig, executive director of the Southeastern Indiana Regional Planning Commission, said she’s been working with Gallardo since last Fall in serving nine rural counties in Southeastern Indiana.
“There were a lot of conversations on the local level before it was finalized to go with the studies,” Craig said about Gallardo’s research of the socioeconomic disparities across Indiana.
Gallardo also said the data may represent what the speeds re advertised as rather than what they actually are.
Still, the project involves legal and financial competence through public-private partnerships. These large-scale processes depend upon these complex factors interfacing with one another. Solving Indiana’s broadband issues means creating a discussion between policymakers and the public as well, Gallardo says.
Scott Rudd, director of broadband opportunities fro Indiana, works with Gallardo on attracting broadband providers to various counties. With help from the Indiana Lt. Gov Suzanne Crouch, Rudd held the 2018 Broadband Summit, “Connecting Hoosier Communities” last October with one of the goals to improve the dialogue between different groups of people such as stakeholders across the state.
Gallardo said,” There is no one-size fits-all model when deploying or upgrading broadband infrastructure.”
-
Data-based analysis reveals data science job prospects
With Purdue University’s Data Science Initiative emphasizing on students having the best skills necessary for jobs, here’s a data-driven look at what the job market will look like.
The job description data came from studies by Corey Seliger, Director of Integration and Data Platforms, ITaP and the web scraping service PromptCloud. The data sets that scraped job posting websites were obtained through the Purdue University Research Repository and the machine learning community Kaggle.

Though Purdue does not offer as many courses from their Data Science Initiative when compared to other schools, this is less of a statement about Purdue’s Data Science Initiative and more of what universities classify as “data science” courses. The interdisciplinary nature of Purdue’s Data Science efforts meant that many courses through various other departments were not counted as data science courses. This analysis did not include, for example, courses from biology or neuroscience departments that may be considered intensive with data analysis.


The Statistics Living-Learning Community’s publication and presentation record since their inception shows the influence the Data Science Initiative has had in getting students’ work published.

The majority of them are in big cities like Chicago and San Francisco. These cities show where the future data science jobs are likely to be. They can be classified with corresponding metrics of predictability.
More data science jobs require a Ph.D. when compared to other education qualifications of Bachelor’s degrees or Master’s degrees. 16,618 require a Ph.D, 10,695 required a Bachelor’s, and 8,759 required a Master’s. Over half of the jobs listed, 82,726 contained no educational requirements.

The associated wordcloud provides another glimpse into the words these job postings most commonly use. Though these words may be used frequently throughout the job postings, their importance to data science as a whole shows by their usage.
The wordcloud shows relative frequencies of each keyword from the job descriptions. Key phrases like “practical experience,” “complex data,” and “strategic tactical” show the types of skills data science jobs require. That jobs requiring these skills means students seeking data science careers should understand them for their career goals.
The data was taken from over 90,000 job postings of data science jobs. The job postings contained various information including salary, background, experience, and personal skills relevant to the job. They emphasized specific skills they look for in applicants and the types of experience required.

Latent Dirichlet allocation (LDA) is a generative statistical model to use unobserved groups that explain why parts of the data are similar to make observations. The LDA analysis of data science job prospects can be found here. With LDA, we observe how keywords or phrases cluster among themselves in groups of principal components. LDA has uses in Natural Language processing and topic modeling for large amounts of text. Modeling texts on various ways their keywords cluster can be used to predict books to recommend to someone based on their previous reading. Publications can model topics to extract key features from articles or cluster articles that are similar close together.
LDA involves estimating topic assignments for key topics in the text. For each document, an amount of topics is chosen and words are generated according to the Dirichlet distribution. Then the model works backwards to figure out how to find a set of topics and corresponding distribution that could generate the document’s content.
It determines how document topics vary among themselves, the words associated with each topic, and the phi value. The phi value is how likely a word belongs to a certain topic. The script, written in the python programming language, takes about 20 seconds to extract and analyze data while outputting results nearly 100,000 job descriptions. The speed of the pipeline came through programming techniques to take advantage of the the similarity between the input files. A multi-threaded procedure was used to run these tasks in parallel with one another and a search approach that saves memory by directly converting the file text to manageable data reduced the pipeline’s runtime from several hours to less than a minute.
Through various sampling methods, LDA can learn how to improve its method of determining the document’s content. We can train the LDA on various known sets of data to learn how to extract features and form predictions.
The process included parsing each file for keywords. This meant removing unnecessary words (such as “and” and “the”) as well as combining similar words into one another (such as “analysis” and “analyze”).
The LDA models can be further optimized for use in sampling such that predictions may be formed on future job prospects in data science. Tools to extract data science job information would prove beneficial for improving the LDA model. Education curricula can reflect these trends in a fluctuating job market. Future work can include finding more varied sets of data such as including machine learning and artificial intelligence keywords in addition to data sciences ones.
Using a support vector machine for classification and data-fitting methods training and testing, the models can be used as the basis for forming predictions on the data science job market. The entirety of these techniques can be found here: https://github.com/HussainAther/journalism/blob/master/src/python/postings/postingAnalysis.py.
